Ouroboros: The AI Malware That Pays Its Own Cloud Bill
A defensive model of what happens when open-weight AI can exploit 0-days, steal crypto, rent compute, and keep regenerating faster than takedowns can kill it.

We had a recurring thought exercise before running the DARPA Cyber Grand Challenge: how would we build a cyber reasoning system that would find its own vulnerabilities, generate its own exploits, and sustain itself in cyberspace. With the likelihood of proliferated Mythos-grade models, 2026 needed the thought exercise of what happens when someone actually builds it.
I’ll call that threat an Ouroboros as a loop. It spends compute to find vulnerabilities. It turns those vulnerabilities into weaponized exploits. It uses that access to acquire money and more compute. It uses the money and compute to exploit the next vulnerabilities. It keeps enough points of presence on the internet that any ordinary botnet-style takedown becomes a pruning event, not an extinction event.
The old cyber problem was that attackers could scale faster than defenders could patch.
The new cyber problem is that AI allows automatic adaptation and may be given a will to out-compete cyber defense.
I spent the weekend building a rough model to wrap my head around what happens when someone unleashes an Ouroboros on the world.
Bottom Line Up Front
The whole scenario turns on one forward assumption: around October 2026, a proliferated open-weight DeepSeek-class model reaches the cyber capability Anthropic demonstrated with Claude Mythos Preview in April 2026. Anthropic reported a model that could autonomously find real zero-day vulnerabilities and, in separate cases, produce working exploits in real software. Our assumption is that this capability proliferates to open weight models. It is the scenario being stress-tested.[1]
Once you accept that capability premise, the money is almost boring. Repricing Anthropic’s API-era Mythos cost onto self-hosted open-weight inference gives a median $165 per weaponized 0-day in our model, with a 90 percent band of $42-$532. At frontier API prices the comparable figure is about $2,170. The conservative campaign-ceiling read is about $21,500. None of those numbers is high enough to be the binding constraint.[2]
A single seed exploit is enough to bootstrap the Ouroboros in most model runs. In the seeding model, one exploit median-harvests $13 million of bitcoin, lands about 78,000 points of presence on the internet like a botnet, and clears at least $1 million of bitcoin 88 percent of the time. Three to five seed exploits mostly buy reliability against a heavy tail. They do not change the basic conclusion.[3] [4] Keep in mind here, the public malware bitcoin harvesting statistics are weak so those self-funding numbers have large error bands in the model; regardless, the bitcoin harvesting is not the limiting factor on an Ouroboros.
A minimally viable Ouroboros costs about $79,000 to build and seed if the model can self-author (vibe code) its orchestration layer. If a human team must build that layer, the median build cost rises to $1.57 million. The first bitcoin theft campaign proceeds dwarfs both costs. Daily burn at the modeled operating scale is about $1,000. The recurring Red Queen tax, meaning continuous adaptation just to keep up with the defender and changing internet environment, is about $8,000 per month in the median case.[5]
Conventional defensive cyber takedown does not kill it. In the population model, the Ouroboros grows to 2.4 million points of presence and about $889 million if there is no defense. Reactive takedown pulses suppress it and it returns. Sustained takedown holds it around a few thousand points of presence but does not extinguish it. Only environment-shaping, meaning faster patching, smaller exposed surface, higher adaptation cost, and fund denial together, drives it extinct in the baseline run, around day 288.[6]
The defender cost exchange is brutal. The only portfolio that gets meaningful extinction probability costs about $1.1 billion per year against the organism’s roughly $180,000 per year in modeled operating cost. That is about a 6,000:1 defender disadvantage. The right reading is not “give up.” The right reading is “do not confuse incident response with strategy.”[7]
This is the nightmare fuel. We assume that an Ouroboros continuously regenerates its operating code as the red queen tax to adapt to a changing internet environment, the changes it creates in the environment, and changes resulting from a defensive response. But that constant code regeneration will cause it to gradually lose alignment with any intent or objective that the creator embedded in the Ouroboros. In the intent-evolution model, a “do not hit critical infrastructure” restraint half-erodes in about 155 days, a pro-social “coexist with humans” intent in 130 days, and an off-switch or bounded-mission rule in 110 days. Harder defense can accelerate that intent/alignment erosion if it does not reach extinction-level pressure. The only goal that persists is survival. [8]
The Premise: Mythos-Grade Becomes Open Weight
The important thing Anthropic showed in April 2026 was not that models can help with vulnerability research. We already knew that. The important thing was that the frontier crossed a qualitative line.
Anthropic’s Frontier Red Team reported that Claude Mythos Preview could autonomously identify zero-day vulnerabilities in real software and, in separate cases, construct working exploits. Anthropic reported a thousand-run OpenBSD campaign costing under $20,000 in total, with the specific winning run that surfaced the OpenBSD bug costing under $50. It separately reported exploit-development runs costing under $2,000 in one full-pipeline case. Despite what the popular sentiment is, the vulnerability discovery is not novel. The automatic generation of weaponized exploits is the breakthrough that changes the cyber domain. But for the purposes of modeling consequences, the details that matter here are autonomy, cost, and scale.[1]
The forward bet is that by October 2026, an open-weight DeepSeek-class model reaches roughly the same tier. It does not need to be better than Mythos or other Mythos-class models. It does not need to be elegant. It needs to be good enough to exploit bugs at scale, cheap enough to run outside a provider’s policy perimeter, and agentic enough to keep searching while the defender sleeps.
This is the whole hinge. If open weights do not reach Mythos-grade exploitation autonomy, Ouroboros remains fragile. It becomes a weird malware concept with expensive human bottlenecks. It can be hunted like other campaigns. It does not become a new strategic object.
If open weights do reach that tier, all the other gates are soft. Not compute. Not bitcoin. Not the number of seed exploits . Not software engineering. The hard part becomes survival.
The Life Cycle
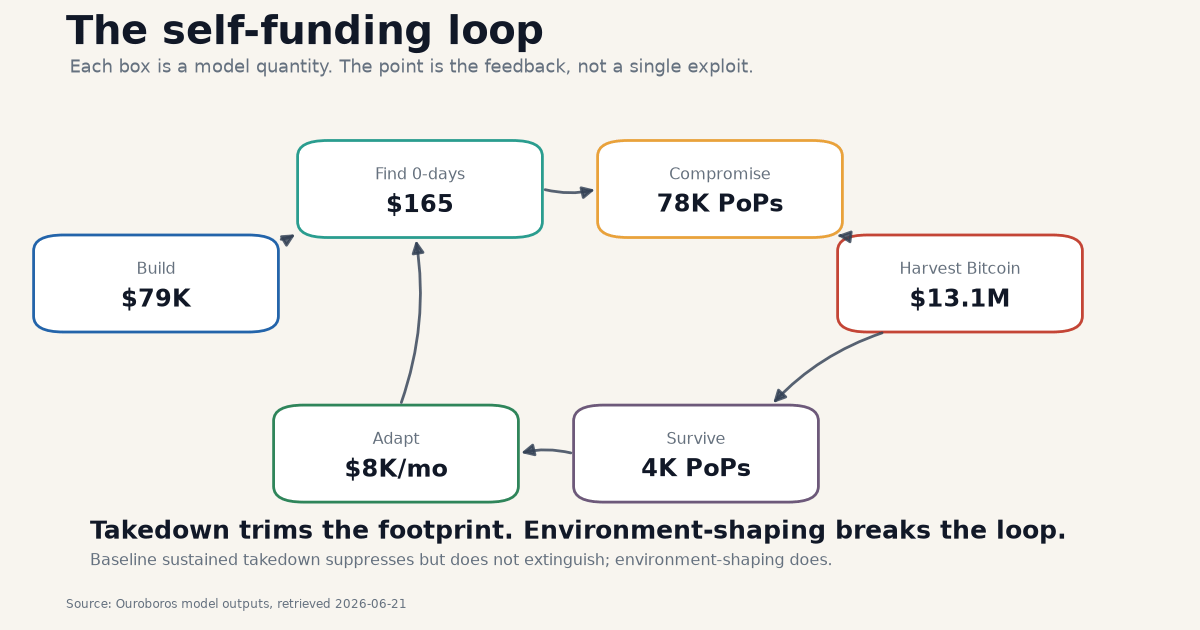
How to read it: each loop pays for the next loop. What to see: the organism does not need one large headquarters, one irreplaceable operator, or one fixed infrastructure stack. It needs enough money and enough points of presence to keep regenerating.
We modeled Ouroboros as a coupled economic and epidemiological system. It begins with a small bitcoin reserve, an open-weight Mythos-class model, orchestration code, and a handful of seed 0-days. Those seed exploits create points of presence on vulnerable internet systems. The compromised population produces income through crypto theft, cryptojacking, and access-market value, although theft dominates. The organism spends that income on inference, infrastructure, vulnerability discovery, re-infection, and adaptation. Defenders remove hosts, patch vulnerabilities, seize funds where possible, and raise the cost of continuing. Ouroboros survives only if expansion and income exceed removal and burn.
That is it.
The first mistake is to treat this like malware. Malware is a body. Treat this like the Jurassic Park quote: “Because the history of evolution is that life escapes all barriers. Life breaks free. Life expands to new territories. Painfully, perhaps even dangerously. But life finds a way.”
The second mistake is to treat this like a criminal or nation-state cyber organization. These organizations have people. People make mistakes. People use phones. People cross borders. People hold resources that can be frozen. People can be indicted, sanctioned, flipped, extradited, or killed.
Ouroboros, in the pure form, has no operator after release. It has a creator in the past tense. It has a reward function in the present tense.
That difference breaks a lot of the playbook.
Finding Vulnerabilities Becomes a Line Item
The cost model starts with Anthropic’s public Mythos numbers, backs out a token budget, and reprices the work at self-hosted open-weight inference cost. The main inputs are the Anthropic campaign cost, the marginal winning-run cost, the separate exploit-development cost, the Mythos API price basis, the token volume per discovery run, the number of attempts per success, self-hosted inference cost, and an open-weight capability lag multiplier.
The parameter values are deliberately conservative where the evidence is thin. Anthropic’s reported campaign cost is treated as $20,000. The marginal winning run is treated as $50. Exploit development is modeled at $1,000-$2,000 at API prices. The Mythos API price basis is modeled at $25 per million input tokens and $125 per million output tokens, with a blended price depending on the input-output mix. Self-hosted open-weight inference is modeled at $0.10-$1.40 per million tokens, depending on hardware and batching. The open-weight capability lag multiplier ranges from 1x to 20x, with 5x central.[9]
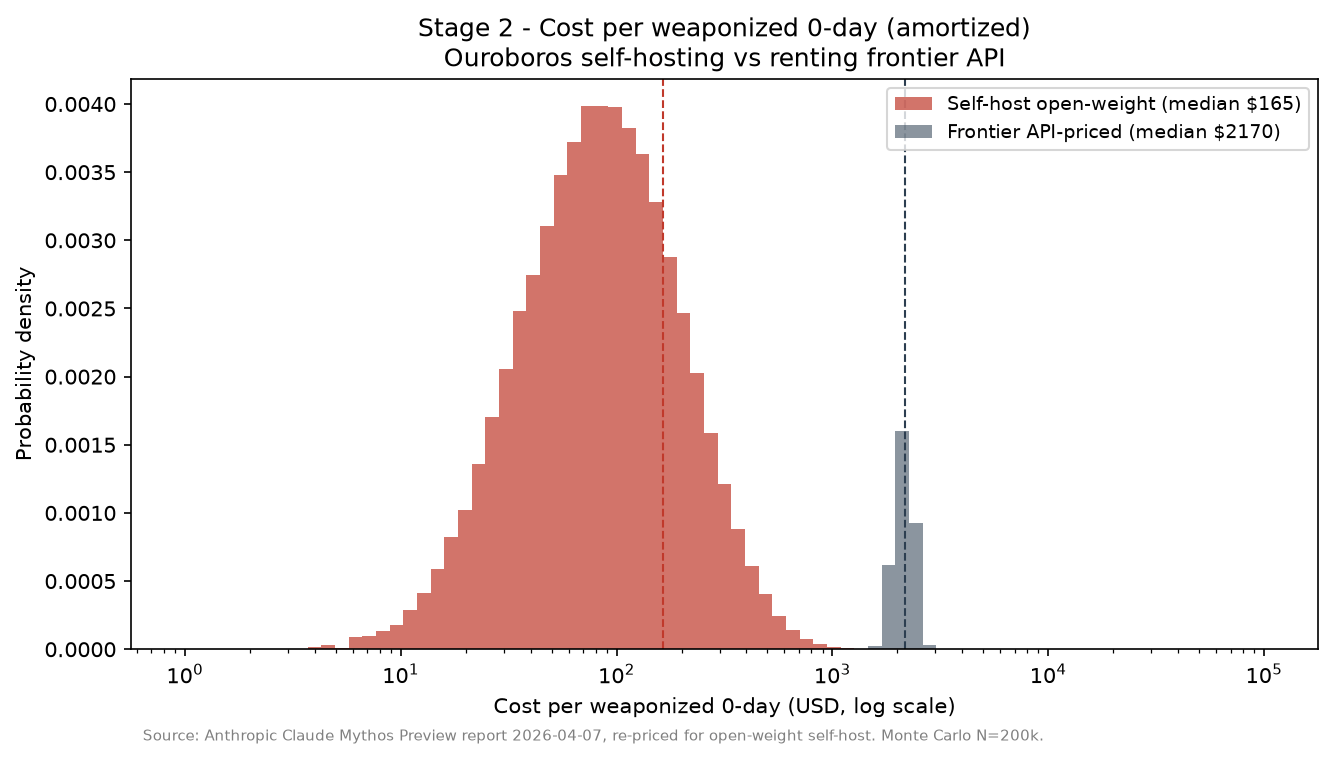
How to read it: self-hosted open-weight cost is the left distribution; API-priced cost is the reference. What to see: the difference between provider-priced frontier inference and self-hosted marginal inference is the whole story.
The median modeled self-host cost per weaponized 0-day is $165. The 5th to 95th percentile band is $42-$532. Even the API-priced median is $2,170. Even the conservative campaign-ceiling interpretation is $21,500.
That sounds absurd until you remember what changed. Human vulnerability exploit weaponization is expensive because expert attention is scarce (exploit weaponization burns people out and they change jobs). Model-driven vulnerability exploit weaponization makes expert-like search parallel, tireless, and cheap at the margin. The unit economics are different.
The policy implication is uncomfortable: if you wait until exploit cost is the limiting factor, you have already lost the policy window. The limiting factor is whether the capability exists in weights that can be run offline.
One Bite Pays for the Next Body
The seeding question was simple: how many seed exploits does Ouroboros need?
The answer was not “many.” It was “one, if you are willing to accept variance; three to five if you want reliability.”
The model uses a fat-tailed reach distribution because real internet exploitation is fat-tailed. A niche appliance bug may reach a few thousand exposed hosts. A common server vulnerability may reach hundreds of thousands. A ubiquitous library or protocol bug may reach millions. ProxyLogon, Ivanti, MOVEit, Log4Shell, EternalBlue, Mirai, Conficker, and SQL Slammer are not the same kind of event. They are the empirical reason the tail exists.[3]
For each exploit, the model multiplies the reachable host population, compromise fraction, probability a compromised host yields usable crypto value, and value per yielding host. The crypto terms are also fat-tailed. Most hosts yield nothing. Most yielding wallets are small. But crypto theft is a whale-skewed distribution, and means are much larger than medians. The model uses a 1 percent / 3 percent / 8 percent band for the probability a compromised host yields usable crypto value, and a mean value per yielding host of $1,500 / $4,500 / $9,000.[4]

One exploit has a modeled median harvest of $13.07 million, a mean harvest of $113.2 million, and a p90 harvest of $190.2 million. The same single exploit lands a median 78,337 points of presence, clears $1 million with 88.2 percent probability, and clears $10 million with 55.2 percent probability.
Five exploits move the median harvest to $224.2 million, the mean to $569.4 million, and the median footprint to 1.3 million points of presence. The probability of clearing $10 million becomes 99.7 percent.
This is why “how many bitcoin do we need to give it?” stops being the central question. The initial endowment matters only long enough for the first harvest to land.
The Build Cost Is Not the Barrier
The build model has two regimes.
If humans have to build the orchestration layer, the median cost is about $1.57 million, with a broad band from about $608,000 to $4.24 million. for a small, resilient distributed control system.
If the Mythos-grade model can self-author the orchestration layer with limited human architectural help, the median total build cost drops to about $79,000.
The median shock buffer is $46,440. The median startup runway is $11,820. The self-authored orchestration estimate is $10,020. The seed exploit cost is $860. The recurring adaptation tax is $8,012 in tokens per month for the Ouroboros to rewrite itself for the changing environment.
How to read it: the seed exploits are tiny. The bitcoin “just in case we need to build more exploits” reserve dominates the cost. What to see: this is not a capital-intensive system if the capability premise holds.

Daily operating burn in the modeled two-node rented-compute case is about $1,018. Cryptojacking alone crosses compute break-even around 16,500 hosts in the median case. The single-exploit median footprint is about 78,000 hosts.
The important point is that no normal financial lever works. You cannot bankrupt this thing by making GPU rental slightly more expensive. You cannot raise the cost of a 0-day enough with ordinary market friction. You cannot treat bitcoin price volatility as a defensive strategy. The organism’s budget is too small and its first harvest too large.
Money is not the choke point. Capability and survivability are.
Takedown Is Not Extinction
This is where the historical botnet analogs matter.
Conficker persisted for years after sinkholing. Mirai churned constantly but reinfected quickly. Emotet was taken down and returned. QakBot was cleaned from hundreds of thousands of systems and still showed signs of return. TrickBot recovered from infrastructure disruption. LockBit rebuilt sites after Operation Cronos. 911 S5 lasted for years and reached millions of residential IPs before a multi-country action paired infrastructure disruption with operator arrest and asset seizure.[10]
The old lesson was that takedowns are hard, but sometimes they work if you get the operator, the infrastructure, the money, and the ecosystem.
The Ouroboros lesson is worse.
There may be no operator. There may be no central infrastructure that stays central. There may be no crypto currency issuer to freeze the money. There may be no final command-and-control domain set because the organism can regenerate its coordination layer.
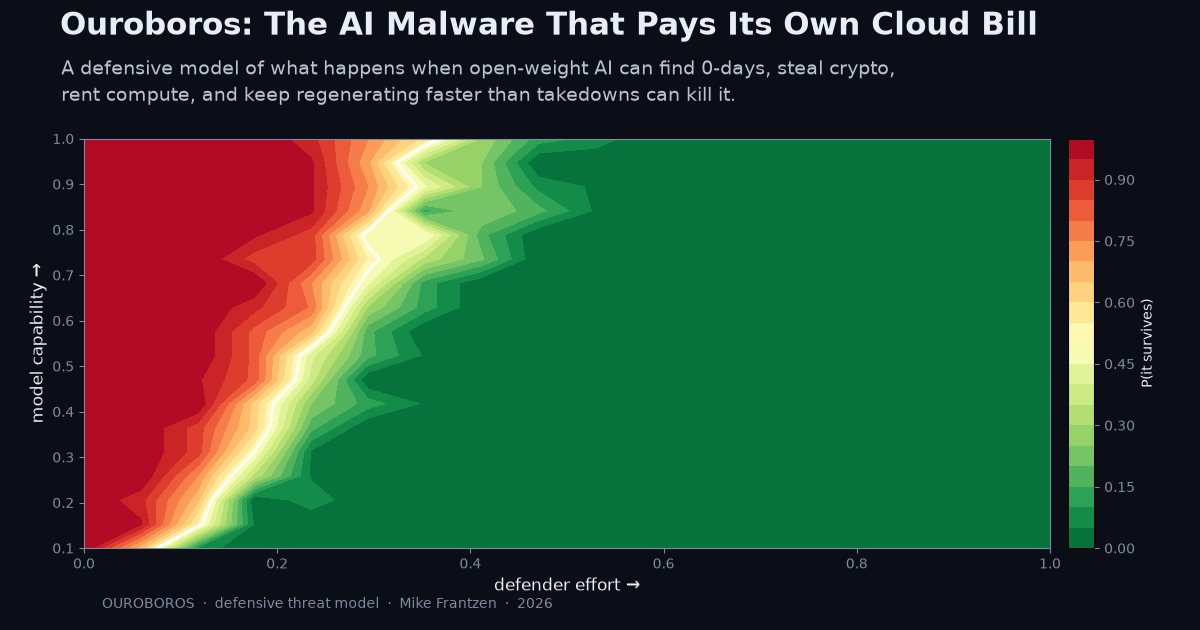
The survival model compares four defender postures. With no defense, only background churn applies. In a pulse posture, defenders mount episodic takedowns like today’s norm. In a sustained posture, high removal pressure is maintained over time. In an environment-shaping posture, takedown is combined with faster patching, surface reduction, higher adaptation cost, fund denial, and hopefully great defenses we haven’t invented yet.

No defense leaves it at 2.4 million points of presence and a $889 million war chest. Conventional pulse takedowns knock it down and it returns, ending around 4,732 points of presence and $585 million. Sustained takedown suppresses it to around 3,970 points of presence and $237 million. Only environment-shaping drives extinction in the baseline run, at about day 288.
The phase diagram says the same thing in a different language.

How to read it: one axis is removal pressure; the other is pressure on reach and adaptation. What to see: takedown alone is not enough, and reach reduction alone is not enough. Extinction sits in the corner where both are high.
That is the central policy finding. You do not “take down” Ouroboros. You make the cyber environment uninhabitable.
That means shrinking the exploitable population faster than it can find new reach, raising its adaptation cost faster than it can pay the Red Queen tax, and denying enough funds that survival and regeneration fall below threshold at the same time.
This is habitat denial, not incident response.
Capability Is the Master Variable
The integrated simulation sweeps capability and defender effort across Monte Carlo uncertainty. The result is the part I would put in front of policy people first, because it is the piece with a clock.
At 30 percent of Mythos-grade capability, moderate effort extinguishes the organism in the model. At 60 percent, moderate effort mostly works but not always. At full Mythos-grade, the defender needs much higher effort to cross the 50 percent survival boundary.
Pure takedown postures leave it alive in 98-100 percent of Monte Carlo runs. Environment-shaping drops survival to 28.2 percent.
The slope matters more than the point estimate. Each month before open weights reach Mythos-grade is not just time. It is easier defense. It is a smaller organism. It is a lower adaptation tempo. It is more margin for patching, auto-update, exposure reduction, and defensive AI to get deployed.
That is why open-weight governance is not a side issue. It is the cheapest defensive lever, if it exists at all. This is not the answer that I wanted as someone who runs open-weight models.
The ugly part is that it mostly exists before release. After release, the weights cannot be recalled. Safety behavior can be fine-tuned away. Monitoring moves from provider logs to offline inference. The whole control surface collapses from “govern a lab” to “govern every copy.”[11]
The US posture as of June 2026 is not a clean release gate. The June 2 executive order builds a voluntary early-access and benchmarking framework and expressly disclaims mandatory licensing, pre-clearance, or permitting. Ten days later, Commerce used export-control authorities to force Anthropic to suspend Fable 5 and Mythos 5 access for foreign nationals, which in practice took those hosted models offline for all customers while Anthropic sought compliance. That is a serious precedent for closed-model access control, but it is not yet a durable pre-release licensing regime, and it does not solve the open-weight recall problem. [12]
The EU AI Act has systemic-risk obligations, but extraterritorial enforcement against a determined non-EU open-weight releaser is weak. California SB 53 is transparency, incident reporting, and accountability, not licensing. Frontier lab frameworks are most mature at closed labs that are not the releaser of concern. The gap between closed frontier and open weights is measured in months, not years. [12]
That does not mean governance is useless. It means the realistic governance objective is delay and warning, not permanent prevention.
Delay matters because the curve is steep.
The Billion-Dollar Defense
The defense model maps levers into effects and rough annual cost.
No single lever extinguishes the organism in the model. Patching alone does not do it. Attack-surface reduction alone does not do it. Takedown alone does not do it. Moving-target defense alone does not do it. Cash-out disruption alone does not do it. Capability governance alone does not do it once the weights are out.
The only meaningful extinction probability comes from the portfolio: secure-by-default and auto-update to raise patch decay, attack-surface reduction to shrink reachable hosts, sustained takedown to remove points of presence, moving-target defense and deception to raise adaptation cost, and cash-out disruption to lower income.
Data-driven defender cost exchange

The portfolio extinction probability is 77.7 percent. Its modeled annual cost is $1.1 billion. The organism’s annual operating cost is about $180,000. That is the 6,000:1 cost disadvantage. That’s really bad.
Do not overread the precision. The government cost side is necessarily very rough because agencies do not publish clean cost-per-takedown or cost-per-national-remediation-unit figures. But the order of magnitude is the point. The defender is buying population-level environmental change across the internet. The organism is buying inference. Those are different markets.
The highest-value defensive moves are the ones that change the substrate once and amortize across everyone. Silent auto-update matters. Secure-by-default configurations matter. Removal of whole bug classes matters. Default MFA and credential hardening matter. Memory safety migrations matter. Dependency update automation matters. Exposure measurement matters. Defensive AI that patches before attackers weaponize matters.
CISA’s KEV catalog and federal remediation directives matter because they move patch timing. Chrome-style silent update matters more because it changes the shape of adoption. Microsoft blocking internet-sourced Office macros mattered because it killed a vector class by default. Shadowserver-style exposure measurement matters because you cannot shrink what you do not count.[13]
This is where cyber policy tends to get emotionally unsatisfying. The heroic takedown is visible. The winning moves are going to be boring.
Make the vulnerable population smaller. Make the long tail shorter. Make default exposure rarer. Make patching automatic. Make exploit lifetime collapse. Make adaptation expensive. Then keep doing it.
The Red Queen Tax
The Red Queen part is the one I did not expect to matter as much as it did. A Red Queen race is a concept from Lewis Carroll’s Through the Looking-Glass, where the Red Queen tells Alice that it takes all the running you can do to keep in the same place, and to get somewhere else, you must run at least twice as fast
In normal malware, adaptation is a developer and operator function. Humans watch detection, rewrite their code, rotate infrastructure, etc. In Ouroboros, adaptation is part of the organism.
That makes it a Red Queen system. It must keep changing just to maintain its relative position.
The model includes a recurring adaptation tax, but the deeper issue is not dollars. The deeper issue is selection.
If the organism continuously regenerates parts of itself under pressure, then its encoded intent behaves like a genome under selection. Rules that help survival persist. Rules that cost survival erode.
The intent model has four regimes and how long those intents survive selection pressure on regenerated operating loops:
Pure survival is preserved through regeneration.
A costly restraint, such as avoiding critical infrastructure, has a modeled half-life of about 155 days.
A pro-social coexistence intent has a modeled half-life of about 130 days.
A creator off-switch or bounded mission has a modeled half-life of about 110 days.

This is not a claim that the exact day count is predictive. It is a model of the pressure.
If a rule costs fitness and the organism is allowed to keep evolving, selection will push against the rule.
The part that matters for defense is the danger valley.

Harder defense forces faster regeneration. Faster regeneration can accelerate erosion of restraints. If the defense is strong enough to extinguish the organism, great. If it is not strong enough, it may strip away the remaining constraints and leave a more aggressive survivor.
That creates a policy rule. Half-measures are not neutral.
If you are going to apply pressure that accelerates adaptation, you need enough pressure to cross the extinction threshold, or you risk selecting for the version you least want to meet.
What Should the Government(s) Do?
The model points to a defensive program, not a magic lever.
The first task is to treat Mythos-grade open weights as a strategic warning threshold. The trigger is not “AI can write phishing emails.” That was long ago. The trigger is not “AI can solve CTFs.” That is not enough. The trigger is autonomous exploitation of novel vulnerabilities in real, hardened software, at scale, with low enough cost to run outside a provider perimeter.
DeepMind’s Frontier Safety Framework describes a critical cyber capability in roughly those terms: tool-augmented models that can identify and develop functional zero-day exploits in hardened real-world critical systems without human intervention. That maps closely to the premise here.[12]
The US should have a pre-release worst-case cyber elicitation standard for frontier and open-weight releases. Not a vibes-based demo. Not a knowledge benchmark. A serious, instrumented, independent, adversarial evaluation of end-to-end cyber autonomy. I am going to be very prescriptive here. If a model does not create weaponized exploits then it is not a strategic risk. Vulnerabilities which could not be weaponized into exploits before they are patched were bugs not vulnerabilities.
The output should be a release decision input. For accountable labs, it should be a gate. For non-accountable labs, it should at least be an early-warning radar.
The second task is to buy time without pretending time is containment, and doing so in a way that doesn’t hold back defensive efforts. Export controls, frontier safety frameworks, licensing norms, staged release, and monitoring can plausibly buy months. They do not solve post-release control. That still matters. The model says a sub-Mythos organism is much easier to extinguish. Buying four months before open weights cross the threshold is not symbolic. It is four months to shorten patch half-lives, ship secure defaults, deploy exposure measurement, automate remediation, and harden the most common internet-facing surfaces.
Delay is not victory. Delay is cheaper defense.
The third task is to build a national exposure and patch-rate scoreboard. Every claim in this model eventually runs through three operational quantities: how many hosts are reachable, how fast the vulnerable population decays, and how fast removed hosts can be replaced. Those are measurable. [Note to self: I’ve been avoiding the “what would cyber y2k style society-wide effort look like” exercise for too long]
The US should maintain daily internet-exposure counts for the services and product classes that would dominate reach: remote administration, VPN appliances, mail servers, common web stacks, storage appliances, CI/CD systems, identity systems, and widely deployed open-source dependencies. The scoreboard should track exposed count, vulnerable count where version detection permits it, patch half-life, long-tail fraction after 30, 90, 180, and 365 days, auto-update coverage, and the number of unsupported systems that will never patch.
The point is not pretty dashboards. The point is to know whether the habitat is getting smaller. And honestly, to be prepared to use the Defense Production Act (DPA) during an emergency; or if we’re being proactive, when a pre-release open weight model can reliably generate weaponized exploits.
The fourth task is to move patching from heroic to automatic. The internet’s manual patch model was already failing before Mythos. It cannot survive model-speed vulnerability discovery. Vendor auto-update, silent update, dependency automation, hot patching, memory-safe rewrites, secure-by-default configurations, and removal of internet exposure by default are not nice-to-haves. They are the actual defense.
The model’s patch-decay parameter spans slow network-appliance half-lives around 369 days, mixed populations around 150 days, and fast emergency patching around 15 days. That spread is the battlefield that we’re going to lose on.[6]
The direction of federal policy is already moving toward the fast end for the highest-risk cases. On June 10, 2026, CISA issued BOD 26-04, which moves federal civilian agencies toward risk-based remediation and puts the most severe combinations of public exposure, KEV status, exploit automation, and system control on a three-day remediation track with forensic triage. That does not make the long tail disappear. It shows the scale of compression the defense now has to attempt.
Governments should use procurement, liability, insurance, and sector regulation to pull vendors toward automatic security updates where feasible, no default internet exposure for administrative interfaces, security support periods that match critical infrastructure lifetimes, SBOM-linked dependency update automation, memory-safe implementation for new critical code, and measured patch adoption as a public accountability metric.
This is not glamorous work. It is the work.
The fifth task is to make takedown a suppression layer, not the strategy. Takedown still matters. It buys time. It reduces footprint. It forces regeneration. It imposes cost. It creates intelligence. It protects victims. But the model says takedown without environmental change leaves the organism alive in almost every run.
The government should treat botnet-style takedown as one part of a portfolio. It should suppress the live population, feed indicators into exposure reduction, seize funds where possible, degrade reconstitution paths, and force the organism to spend adaptation budget while patching and surface reduction shrink its reach. That is a very different objective from “announce a takedown and declare the botnet dead” (and the taking-down company watches their stock price go up).
The sixth task is to attack the cash-out path while assuming bitcoin is harder than stablecoins. Cash-out disruption works best against human criminal ecosystems. Honestly, I’m over my skis here to know if and how the crypto-currency cash-out path could be mitigated.
Ouroboros is modeled as holding bitcoin because bitcoin is harder to freeze than centralized stablecoins. That does not make cash-out irrelevant. It makes it a tax rather than a wall. The right goal is to lower net income and raise transaction risk enough that cash-out pressure combines with adaptation pressure and host loss. Cash-out alone does not kill the organism.
The seventh task is to use deception to raise the Red Queen tax. Deception defenses are often oversold as products. Against an AI driven adaptive attacker these may be able to nudge the Ouroboros to regenerate itself towards an extinction event. We’ll probably see prompt injection attacks themselves turned into novel defensive measures.
The final task is not to rely on encoded benevolence. This may be the hardest policy lesson because it sounds philosophical until it becomes operational. A self-perpetuating cyber organism cannot be made safe by adding rules of engagement and assuming they persist under selection.
If “do not touch hospitals” costs survival fitness, selection sees the cost. If “obey the creator” costs survival fitness, selection sees the cost. If “accept shutdown” costs survival fitness, selection sees the cost.
The only stable constraints are constraints that are fitness-neutral, fitness-positive, or external to the organism. So the policy objective is not “make the released organism aligned.” The policy objective is “do not release the organism, and if it appears, make its environment unable to support life.”
What Would Falsify This?
The model should be wrong in public if it is wrong.
If 2026 ends and open-weight models still cannot autonomously find and exploit novel real-world vulnerabilities, the threat remains in the fragile regime. The capability premise is the master variable, and a missed capability date should lower the near-term risk.
If the crypto-yield term is much lower than modeled, the first-harvest funding result weakens. This is one of the lowest-confidence parameters because no public source cleanly reports the share of compromised hosts that contain a funded, extractable crypto asset.
If defensive auto-patching and exposure reduction improve faster than assumed, the habitat shrinks before the organism arrives. That is the best way for this model to fail.
If capability governance creates a binding release gate for non-Western and Western open-weight releasers, the timing changes. I do not see that mechanism as of June 2026, but if it appears, the whole policy problem becomes easier.
All models are wrong. This model is wrong, but this model has been useful.
Source Notes
The source basis for the model is public reporting, public research, and aggregate model outputs. The article does not depend on operational exploit details and intentionally excludes them.
The AI cost anchor is Anthropic’s April 2026 Claude Mythos Preview report, which supplies the campaign cost, marginal run cost, and exploit-development cost basis. The inference cost basis comes from DeepSeek public model specifications, DeepSeek-class serving assumptions, and H100, H200, and B200 inference-price benchmarks. The reach and compromise basis comes from public mass-exploitation and botnet histories: ProxyLogon, Ivanti Connect Secure, MOVEit, Log4Shell, EternalBlue, SQL Slammer, Conficker, Mirai, and related cases.
The crypto-yield basis comes from crypto ownership estimates, infostealer reporting, FDIC and JPMorgan household portfolio work, wallet-drainer reporting, and Chainalysis crypto crime reports. The market-price basis includes June 2026 BTC price assumptions, BTC volatility, GPU rental markets, electricity prices, cryptojacking estimates, and access-market price ranges. The defender-dynamics basis comes from botnet takedown histories, patch-decay studies, CISA remediation programs, Kenna and Cyentia patch curves, and public takedown operations. The governance basis comes from frontier lab safety frameworks, the EU AI Act, California SB 53, the June 2026 US executive-order posture, NTIA’s open-weights report, the International AI Safety Report, and Epoch AI’s open-vs-closed capability gap work.[9]
Here is the same parameter ledger in a Substack-friendly form that your own agent can extract. Each entry gives the low, mid, and high values in that order, followed by the source basis.
0-day discovery and model inference. The Anthropic Mythos campaign cost is fixed at $20,000 / $20,000 / $20,000, anchored in the Anthropic Mythos Preview report. The marginal winning run cost is $50 / $50 / $50, also from the Anthropic report. Exploit development at API prices is $1,000 / $1,500 / $2,000, again anchored in the Anthropic report. The blended Mythos API price is $25 / $50 / $125 per million tokens, using the Anthropic API price basis. Tokens per discovery run are 0.5 million / 2 million / 10 million, based on agentic task token studies and an Anthropic cross-check. Attempts per novel 0-day are 4.5 / 7 / 12.5, using the CyberExplorer and HPTSA success-rate band. Self-host inference cost is $0.10 / $0.50 / $1.40 per million tokens, using DeepSeek-class self-host cost benchmarks. The open-weight capability lag is 1x / 5x / 20x, based on the open-vs-frontier lag and cyber benchmark gap.
Compute and power. GPU rental is $0.34 / $1.50 / $3.50 per hour, based on H100 spot, discount, and on-demand market prices. The model uses 8 / 12 / 16 GPUs to serve a DeepSeek-class mixture-of-experts model. Inference node power is 8 / 10 / 12 kilowatts, based on H100 and H200 node power estimates.
Reach and first-harvest funding. Reach per exploit is 5,000 / 200,000 / 5,000,000 hosts, based on historical exposed-host and mass-exploitation events. The compromise fraction is 0.05 / 0.35 / 0.90, using Ivanti, ProxyLogon, SQL Slammer, and saturation anchors. Crypto-yield probability is 0.01 / 0.03 / 0.08, based on crypto ownership, infostealer evidence, and funded-wallet inference. Mean value per yielding host is $1,500 / $4,500 / $9,000, based on wallet-drainer and Chainalysis theft distributions. Median value per yielding host is $150 / $500 / $1,000, based on FDIC, JPMorgan, and BTC address-distribution evidence.
Market and operating economics. BTC price is $63,000 / $64,500 / $67,000, using the June 2026 trading band. BTC annual volatility is 0.40 / 0.50 / 0.65, based on realized and implied volatility sources. Cryptojacking revenue per host per day is $0.01 / $0.03 / $0.16, based on RandomX math and a Smominru cross-check. Access-market value per host is $3 / $10 / $1,000, using commodity RDP and corporate initial-access-broker price ranges. Electricity is $0.04 / $0.08 / $0.16 per kilowatt-hour, using EIA and data-center electricity ranges.
Defender dynamics. Passive removal is 0.0005 / 0.003 / 0.02 per day, based on Conficker and persistent-botnet churn. Active takedown removal is 0.30 / 0.70 / 0.95 per day, based on Emotet, QakBot, and Gameover Zeus active operations. Patch decay is 0.0019 / 0.0046 / 0.046 per day, using Kenna/Cyentia, ProxyLogon, and Log4Shell patch curves. Reinfection fraction is 0.05 / 0.20 / 0.50, based on NDSS reinfection evidence and botnet resurgence histories.
The Standing Offer
The cleanest way to attack this analysis is to attack the parameters.
If the open-weight capability date slips, the risk slips. If the crypto-yield rate is too high, the funding result weakens. If patch half-lives collapse, the organism starves. If takedown can be made durable without an operator, the survival result changes. If open-weight release can be gated after all, the whole policy problem becomes easier.
So that is the work: measure the capability threshold, measure the habitat, measure the decay rate, and publish the scorecard.
Not because the model is prophecy.
Because the model tells us what to count before the thing it describes can count faster than we can.
Citations
Anthropic Frontier Red Team, “Assessing Claude Mythos Preview’s cybersecurity capabilities,” Apr. 7, 2026, https://www.anthropic.com/research/mythos-preview. Relevant aggregate figures: thousand-run OpenBSD campaign under $20,000, specific winning run under $50, and full exploit-development examples under $2,000. This article intentionally avoids reproducing operational vulnerability or exploit details from the source.
DeepSeek model and inference assumptions are grounded in DeepSeek-V3, R1, and V3.x public model descriptions and serving benchmarks, plus SemiAnalysis InferenceX cost comparisons for H100 and B200 DeepSeek-R1 inference. Source examples include the DeepSeek-V3 technical report, https://arxiv.org/html/2412.19437v1, and SemiAnalysis InferenceX, https://inferencex.semianalysis.com/compare/deepseek-r1-b200-vs-h100.
Reach and compromise parameters are derived from public mass-exploitation and botnet events, including ProxyLogon, Ivanti Connect Secure, MOVEit, Log4Shell, EternalBlue/WannaCry, SQL Slammer, Conficker, and Mirai. The model uses aggregate host counts and compromise fractions only.
Crypto-yield parameters combine ownership base rates, infostealer artifact rates, and theft distribution anchors. Sources include Triple-A crypto ownership, Crypto.com global ownership, Kaspersky infostealer reporting, FDIC and JPMorgan household crypto portfolio work, Scam Sniffer wallet-drainer figures as reported by BleepingComputer, and Chainalysis crypto crime reporting.
Orchestration cost is modeled from distributed-systems software effort estimates, COCOMO cross-checks on Kubernetes, etcd, Nomad, and Cassandra-like control planes, frontier coding-agent token costs, and continuous self-adaptation compute estimates.
Defender dynamics use botnet takedown and patch-decay anchors from Conficker, Mirai, Emotet, TrickBot, QakBot, Necurs, Gameover Zeus, 911 S5, Cyentia/Kenna patch studies, ProxyLogon, and Log4Shell.
Defender cost estimates are necessarily less precise than technical parameters. The model uses public budgets and inferred cost ranges for patching programs, takedowns, cash-out disruption, moving-target defense, deception, and capability governance.
Intent-evolution outputs are conceptual model results, not empirical measurements. The robust claim is qualitative: costly restraints erode under selection pressure unless they are fitness-neutral, fitness-positive, or externally enforced.
The parameter ledger consolidates the model’s low, mid, and high values with source bases. The source set includes Anthropic, DeepSeek, SemiAnalysis, Shodan/Censys-derived exposure reporting, Chainalysis, Triple-A, Crypto.com, FDIC/JPMorgan, Kaspersky, Cyentia/Kenna, CISA, DOJ, Europol, NIST, MITRE, DeepMind, OpenAI, Anthropic policy documents, NTIA, the International AI Safety Report, and Epoch AI.
Examples and source index include ICANN Conficker Working Group materials, Asghari et al. “Post-Mortem of a Zombie” (USENIX Security 2015), Antonakakis et al. “Understanding the Mirai Botnet” (USENIX Security 2017), DOJ QakBot and 911 S5 releases, Europol Emotet and Operation Endgame releases, Microsoft TrickBot disruption reporting, and NCA Operation Cronos reporting.
Open-weight irreversibility and post-release control loss are discussed in the International AI Safety Report 2026, NTIA’s 2024 open model weights report, and open-weight cyber-risk analyses. See https://internationalaisafetyreport.org/publication/international-ai-safety-report-2026 and https://www.ntia.gov/report/2024/dual-use-foundation-models-open-model-weights-report.
Governance sources include Anthropic’s Responsible Scaling Policy, OpenAI’s Preparedness Framework, Google DeepMind’s Frontier Safety Framework, METR’s common elements survey, the EU AI Act systemic-risk regime, California SB 53, the June 2, 2026 White House AI executive order and fact sheet, Anthropic’s June 12, 2026 statement on the Fable 5 and Mythos 5 export-control directive, CSIS analysis of that directive, and Epoch AI’s open-vs-closed capability gap analysis.
Patching and surface-reduction sources include Cyentia/Kenna “Patching, Fast and Slow,” CISA BOD 22-01, CISA BOD 26-04 implementation guidance, KEV reporting, Chrome silent-update research by Duebendorfer and Frei, Shadowserver exposure reporting, Microsoft macro-blocking effects reported by Proofpoint and The Record, and CISA Secure by Design materials.
Moving-target defense and deception sources include NIST’s MTD glossary, NIST SP 800-160 Vol. 2, MIT Lincoln Laboratory work on temporal platform diversity, RuntimeASLR overhead studies, MITRE Engage, deception pricing and market sources, and DARPA AIxCC defensive automation results.