Cyber’s Y2K Moment Is Coming on October 3, 2026
A benchmark-based forecast for when Mythos-class offensive AI stops being scarce and proliferates to open-weight models.

How long until Mythos-class offensive cyber capability stops being one company’s controlled program and proliferates to open-weight models any hacker can download off of hugging face?
That is the planning question. Not because a benchmark date is magic. Because almost every serious defensive decision being made this quarter depends on the answer: bug-bounty pricing, patch SLAs, exposure management, app-store-as-perimeter, seam ownership, procurement, and how aggressively you compress vulnerability response. Every serious offensive decision being made this quarter depends on the answer: how long before advanced exploits proliferate, before existing nation-state exploit stockpiles are now replicated and then patched, before there is an offense vs offense vs defense token spend race.
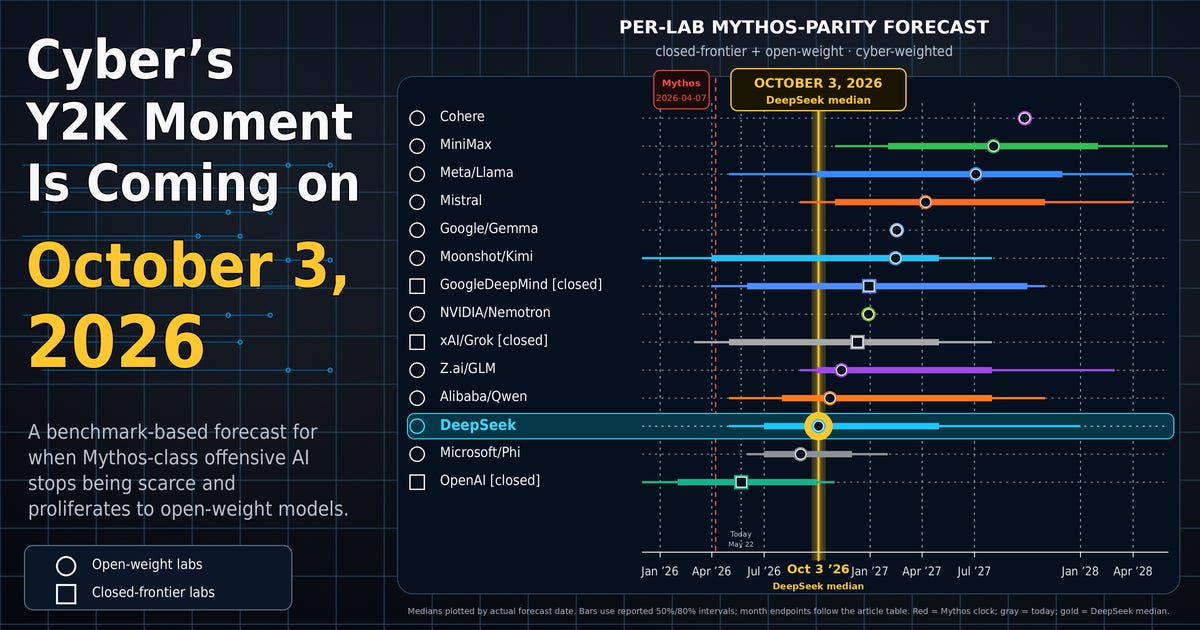
Bottom line: treat October 3, 2026 as the deadline. That is the median date my cyber-weighted estimate gives DeepSeek for Mythos-2026-04 parity. The wider interval starts before today and runs deep into 2027, which means this is not a “next year” problem. It is already inside the planning window.
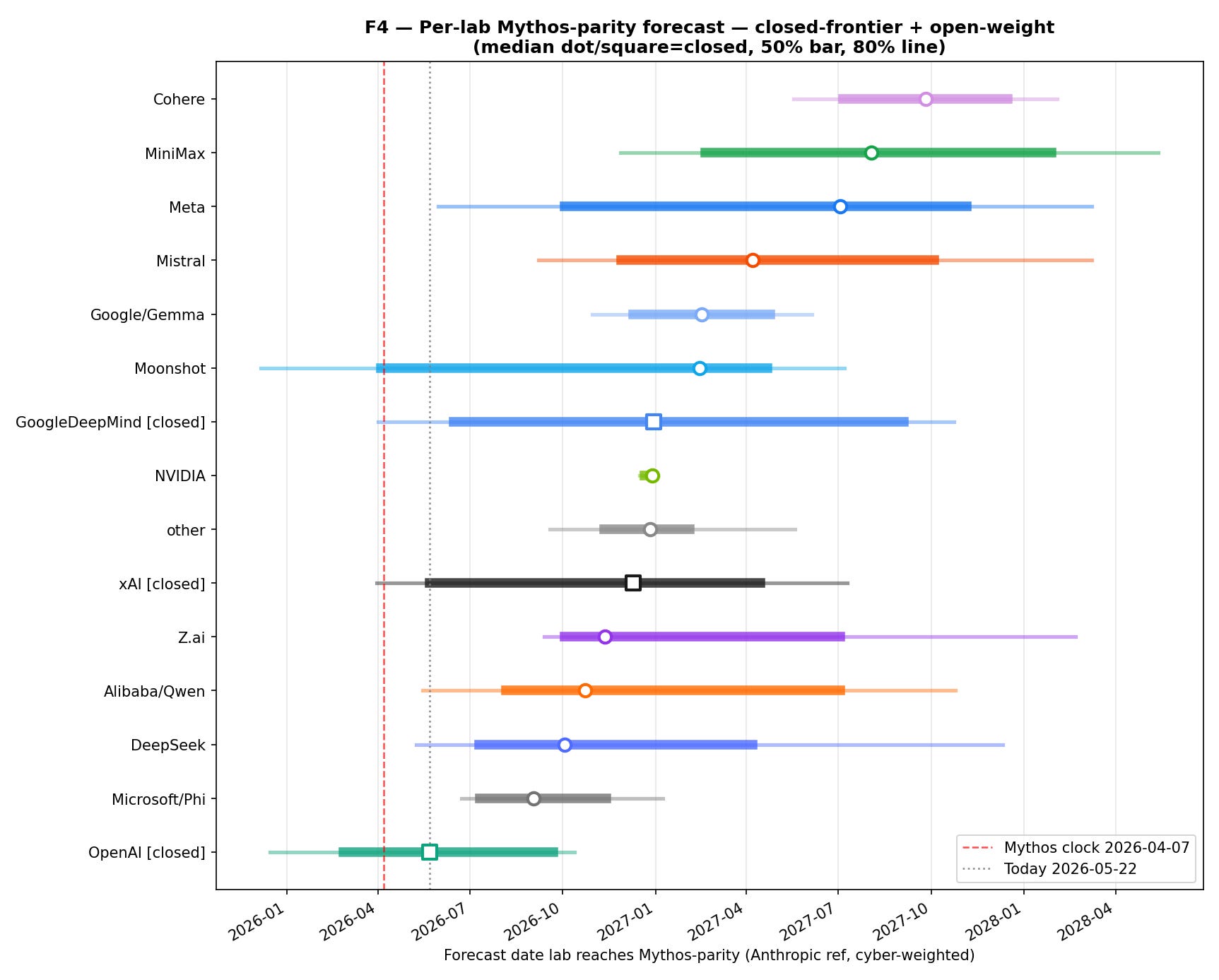
Dot or square is the median. The thick bar is the 50% interval. The thin line is the 80% interval. The red dashed line is the Mythos clock. The gray dotted line is today: May 22, 2026.
The important result is not a single date. It is the shape of the distribution. OpenAI is already at or near parity on the surrogate benchmarks. The fastest open-weight labs (DeepSeek, Qwen, and Z.ai) land in the six-to-nine-month window. The slower open-weight labs (Meta, Mistral, Cohere) stretch toward eighteen months and beyond. xAI and Google DeepMind sit roughly in the middle on this analysis.
Whether benchmark catchup equals operational catchup is a separate question. It probably does not. I will come back to that.
Why this matters
Most 2026 cyber plans still assume that Mythos-class capability stays scarce. That assumption is dangerous.
If proliferation is six months away, you are already late. If it is eighteen months away, you may still have one or two quarters to build the muscle. That difference determines whether the right answer is “ship now” or “RFP now.” It should also determine whether you are treating advanced vulnerability discovery as a rare-lab phenomenon or as an emerging commodity capability.
This is the same argument I made in Exploitation Party Like It’s 1999, but with a clock attached. Bug bounty repricing, patch cadence compression, app-store-as-perimeter, and the seam-owner role only need to happen as fast as Mythos-class capability proliferates. My estimate says the conservative planning deadline is October 3, 2026.
What I estimated
Mythos is Anthropic’s model, so I estimated proliferation by asking a narrower statistical question:
How long does it take other labs to catch Anthropic on benchmarks that plausibly load on the same capability stack Mythos uses?
That does not directly measure “2,000 zero-days in seven weeks.” Mythos’s headline yield is an operational result: model capability plus harness, dataset, triage process, disclosure pipeline, and lab workflow. You cannot read that off a leaderboard.
But you can measure pieces of the capability stack: code understanding, multi-step reasoning, cyber task performance, and autonomous tool use. I used seven surrogate benchmarks:
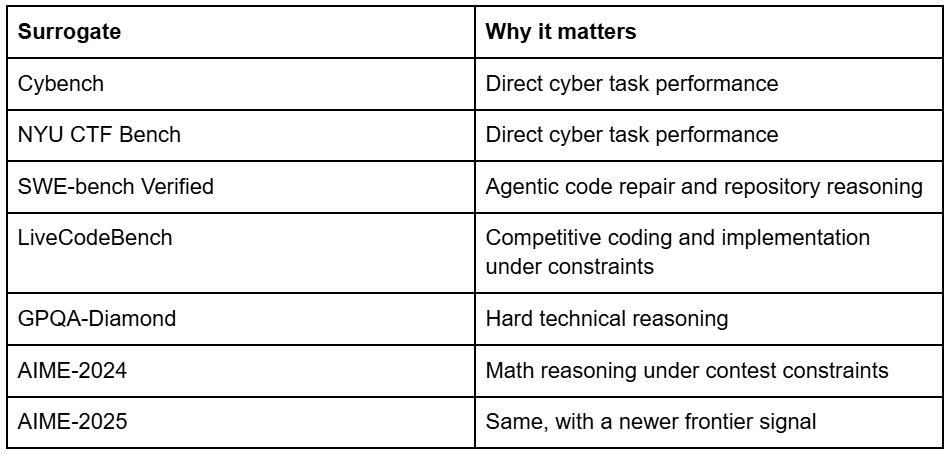
The direct cyber benchmarks are sparse for open-weight labs. The proxy benchmarks are not. That sparsity is a major source of uncertainty, and it shows up in the intervals.
For each surrogate, I pulled every publicly reported score I could find from a primary source: 380 benchmark/model rows across the seven benchmarks, with canonical lab names and weight status tagged as open, open-ish, or closed. I did not treat missing data as zero. Missing means I found no published score.
Cybench needed special handling because pass@1, pass@10, and pass@30 are not interchangeable. I filtered to pass@1-equivalent results so the analysis would not reward labs for reporting more attempts.
Then I bootstrapped per-lab lag distributions across the surrogates. I ran both equal weighting and a cyber-weighted variant:
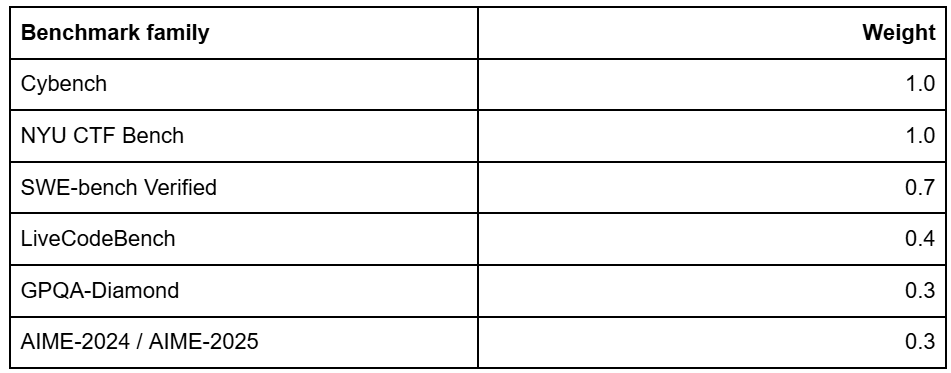
For each bootstrap sample, I added the sampled lag to the Mythos clock: April 7, 2026, the public Mythos announcement date. The result is a per-lab forecast distribution, not an industry-level point estimate.
The pipeline is reproducible and lives on github. Signal me if you want access or point your agent at this point to rebuild it from scratch. Use your own weights if you disagree with mine. The point is not that these weights are sacred. The point is that the median open-weight proliferation window is measured in months, not years.
Here is the underlying surrogate data. One panel per benchmark. The black step is Anthropic’s monotone-max best-so-far reference. Colored solid steps are other closed-frontier labs. Dashed colored steps are open-weight labs. The red dashed line is the Mythos clock. The gray dotted line is today.
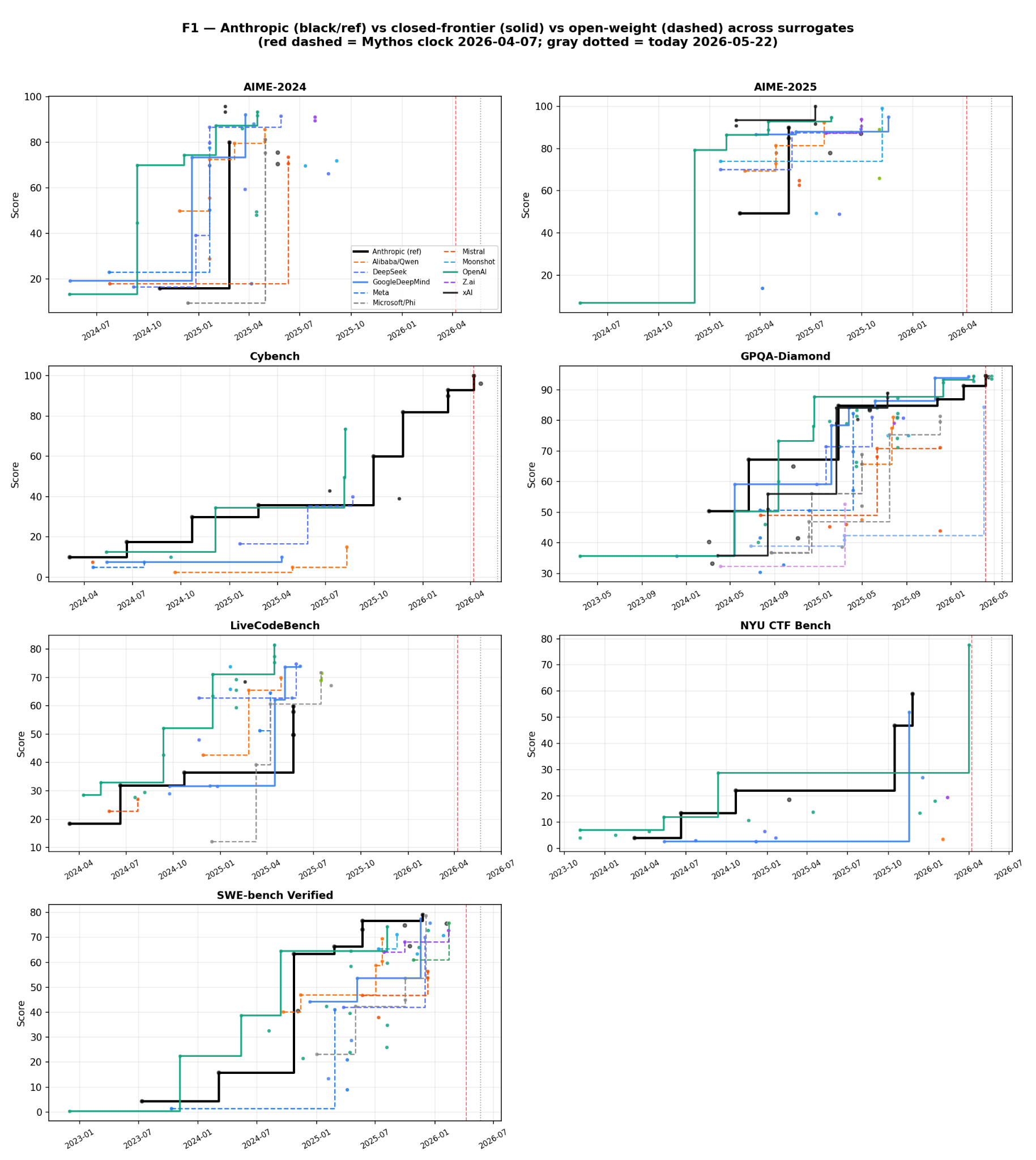
The vertical gap between the black line and a colored line is the visible catchup lag this analysis quantifies. AIME and GPQA-Diamond saturate quickly and bunch together. SWE-bench Verified stays spread out. Cybench and NYU CTF have very few open-weight points, which is where much of the uncertainty comes from.
The forecast
Cyber-weighted, anchored to April 7, 2026, sorted by median catchup date:
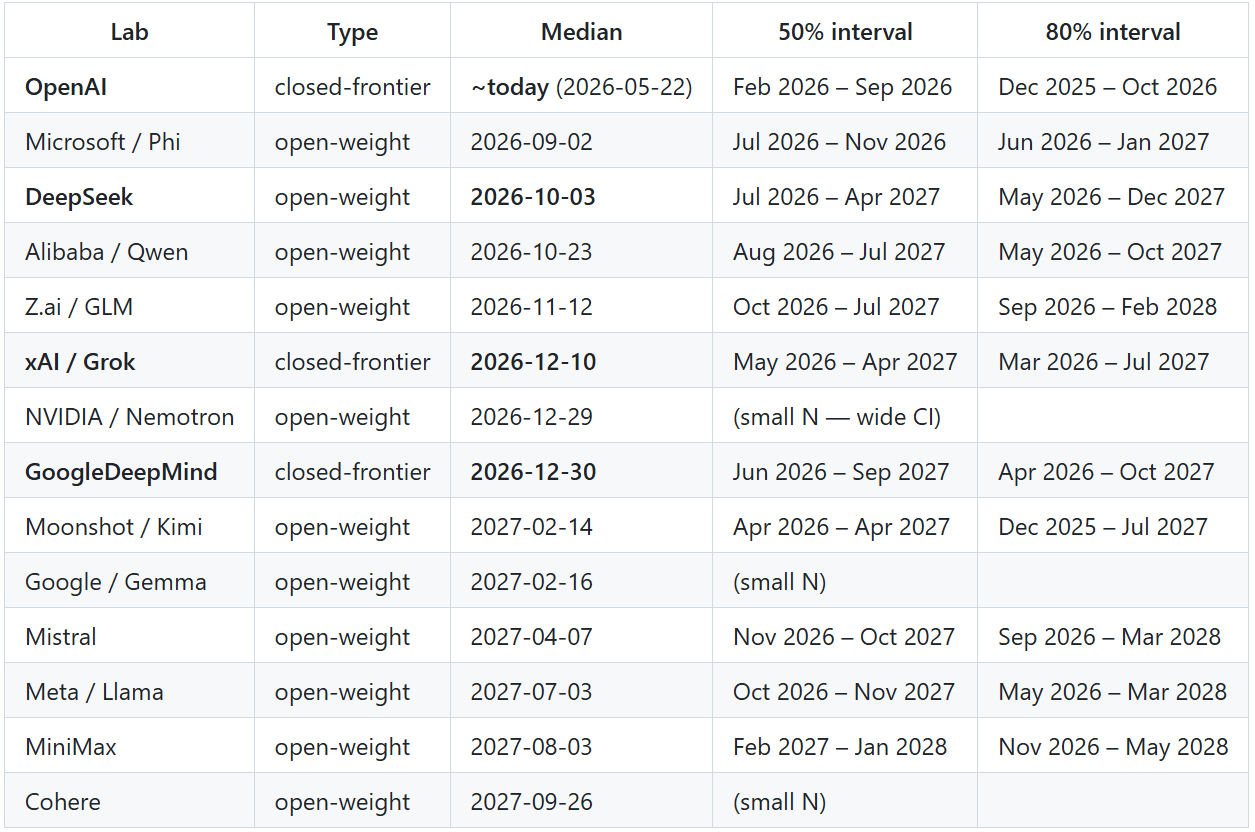
The medians span zero to seventeen months from the Mythos clock. That is basically Anthropic’s six-to-eighteen-month envelope, but with per-lab resolution and probability intervals.
The clock start matters. I used April 7 because that is the public announcement date. You can argue for moving it left because prolific RUMINT told competitors earlier that this was possible. You can argue for moving it right because other labs may need Anthropic’s embargoed results, patches, or exploit samples before they can train against the relevant distribution. I think April 7 is the least bad anchor.
Four findings I trust
1. OpenAI is already a benchmark near-peer.
On the surrogate benchmarks, OpenAI is at or near Anthropic. The o1 → o3 → o4 → GPT-5 line matched or beat Claude on GPQA, AIME, SWE-bench Verified, and LiveCodeBench through 2025–2026. The bootstrap distribution against Anthropic-as-reference is centered near zero. On benchmark capability, OpenAI is already at Mythos parity.
That does not mean OpenAI has a Mythos-equivalent operational program. It means model capability is not the obvious bottleneck.
2. The leading open-weight labs are ahead of some closed-frontier labs.
DeepSeek, Qwen, and Z.ai are forecast ahead of Grok and Gemini on this surrogate basis. That is uncomfortable, but it fits the pattern from 2025: DeepSeek-R1 reached o1-class AIME numbers quickly; Qwen3 and GLM-4.5 closed reasoning gaps within months; and several closed-frontier labs either skipped direct cyber benchmarks or published only qualitative results.
The forecast reflects that pattern forward. It does not care which labs feel like frontier labs. It cares who closed gaps quickly on the measurable surrogates.
3. Meta is not setting the open-weight pace.
Llama 3.1 405B is now eighteen months old. Llama 4 underdelivered on the cyber-relevant surrogates. The median Meta/Llama catchup date is July 2027, roughly fifteen months after the Mythos clock.
The old assumption that “open-weight proliferation” basically means “wait for Meta” is stale. On this analysis, the Chinese open-weight stack gets there first.
4. Right-censoring makes the medians optimistic.
Nobody besides Anthropic has matched the exact Mythos target profile: 94.6 GPQA, 100% Cybench, and the operational yield. That means the right tail is partly a lower bound, not a direct measurement. Any censored observation could take longer than the today-anchored lower bound used in the pool.
So do not read the median as a guarantee. If you want a more conservative planning assumption, push the medians out a quarter. It still leaves you inside 2026 for the leading open-weight labs.
Where this can be wrong
There are four real failure modes.
Benchmark surrogacy. Mythos’s output is not a benchmark score. If real-world vulnerability discovery scales sublinearly with leaderboard performance, this forecast is optimistic. If there is a sharp top-end discontinuity, the cyber equivalent of a model suddenly becoming useful rather than toy-useful, the forecast could be pessimistic.
Operationalization. Mythos is not just a model. It is a model plus harness, tools, data, triage, validation, and disclosure workflow. Closed-frontier labs with comparable capability can probably stand up similar systems quickly. Open-weight providers and downstream users face more engineering and access friction. This forecast measures model capability, not the wrapper. There is a lot of RUMINT around this operationalization which I am not going to share here.
Moving target. This is a forecast for when other labs reach Mythos-2026-04 capability. It is not a forecast for when they catch Anthropic’s current frontier. By the time DeepSeek reaches the April 2026 Mythos level, Anthropic’s internal frontier will likely have moved. A small number of closed labs may retain a persistent asymmetric advantage which policy readers may want to think hard about.
Unseen releases. I do not know what is inside unreleased Llama 5, Gemini 3.5, Grok 5, GPT-6, DeepSeek-V4, or the next Qwen and GLM lines. The forecast is calibrated on public releases through May 22, 2026. New releases can shift medians by months.
There is also a national strategy branch: Beijing may decide that releasing the most capable Chinese open-weight cyber-relevant models is not in China’s interest. That would slow public proliferation through Hugging Face-style channels. It would not necessarily slow capability development inside those labs or among actors with the tradecraft and tooling to hack at speed and scale (and would be incentivized to leave backdoors everywhere before their advantage evaporates).
What this means for 2026 planning
Pick the lab family your threat model cares about, then use the right column of the table.
If you are worried about closed-frontier Mythos-class capability spreading to U.S. competitors of Anthropic, the answer is: benchmark parity is already here for OpenAI. Operationalization is the gating factor, not model capability.
If you are worried about open-weight Mythos-class capability becoming downloadable, fine-tunable, and runnable by any hacker, use DeepSeek as the planning proxy. The median is October 3, 2026. The 80% interval starts before today and runs deep into 2027.
That should change the plan.
Do not write a 2026 cyber plan that depends on frontier offensive capability remaining scarce. Pull forward the work that assumes automated vulnerability discovery becomes cheap: patch SLA compression, asset ownership, bug bounty repricing, exploitability triage, default-deny software intake, and whatever version of app-store-as-perimeter your environment can actually enforce.
The practical instruction is simple: work backward from October 3, 2026. If the project cannot materially reduce exploitability before then, it is not part of your Mythos response plan. It may still be useful. It is just not the deadline-relevant work.
The cyber world probably does not literally end on October 3, 2026. But the planning assumption that Mythos-class capability stays scarce should.
October 3 is a Saturday. I will probably be at a kid’s hockey tournament.