The Masthead Is Not the Moat
Frontier AI labs look dependent on a few famous researchers, and a pile of GPUs. The data says they're robust organizations, and a pile of GPUs.

BLUF
Frontier AI labs do not appear to be brittle around famous senior researchers. The data shows that famous departures do not slow release cadence, do not shrink benchmark improvements, and do not carry productivity to destination labs within a year. The personnel signal points backward: strong labs shed recruitable senior people, weaker labs hire them. As long as they have compute, the AI labs are not brittle organizations.

There is a useful story about frontier AI labs. It says these companies are brittle. (Hint, it’s wrong)
The story is intuitive. Frontier models look like the product of a few extraordinary people, a mountain of compute, and a lot of organizational theater wrapped around both. The chief scientist leaves. The post-training lead leaves. The Llama team leaves for Mistral. The research flavor of the day walks out of the building. Six to eighteen months later the lab should stutter.
I believed a version of that story when I started this project. I expected that the data would prove that story.
Price’s Law gives the story a little math. In a research organization of N people, roughly the square root of N people produce half the output. If a frontier lab has 800 researchers and engineers, sqrt(800) is 28. On that model, twenty-eight people carry half the freight. Pull out three or five or eight of them and the release pipeline should not keep moving as if nothing happened.
So I built the study I expected would find the crack.
It did not.
The setup
The dataset covers 15 frontier AI labs: OpenAI, Anthropic, Google DeepMind, Meta, xAI, Mistral, Cohere, Inflection, Adept, Character.AI, Reka, AI21, DeepSeek, Alibaba Qwen, and 01.AI.
Three research streams gathered the inputs independently before correlation time:
157 model releases from 2020 through May 2026.
171 named personnel events, split across arrivals and departures, with seniority tiers.
174 benchmark scores across epoch-appropriate frontier benchmarks.
35 disclosed compute milestones, normalized to H100-equivalent where possible.
The first five tests were pre-registered. The headline one was simple: after a senior departure, does the lab ship its next major model later than its own historical cadence?
If frontier labs are brittle in the way the story implies, the answer should be yes. The founder leaves, the next major release slips. The research lead leaves, the benchmark trajectory bends downward. A senior researcher moves from lab A to lab B, lab A slows and lab B speeds up.
That is the shape of the prediction.
The data went the other way.
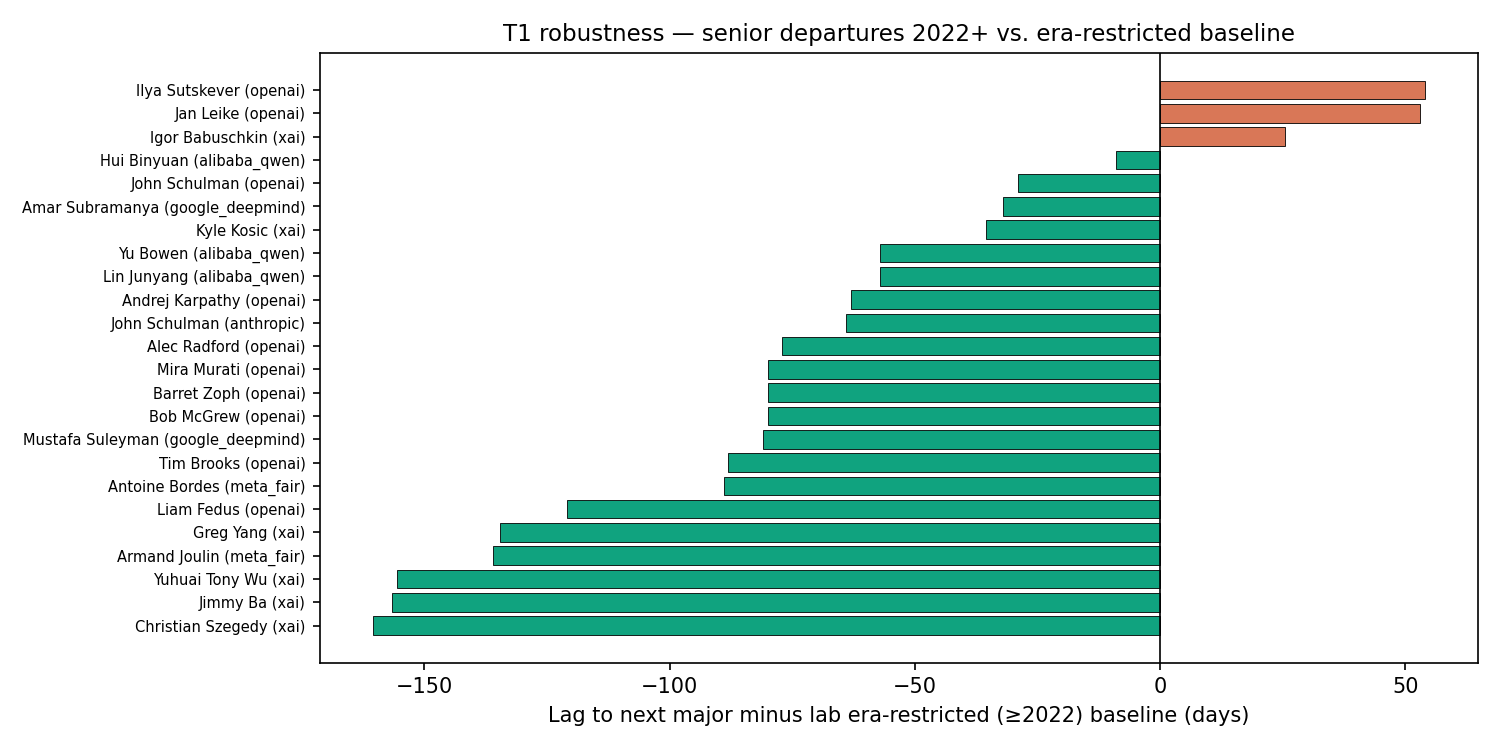
Among 24 senior departures from 2022 onward, 21 were followed by a faster-than-baseline next major release. The median delta was negative 78.5 days. In plain English: the median lab shipped its next major release 78.5 days faster than its own baseline after a senior person left.
That is not what a brittle organization looks like.
Maybe the baseline was doing something weird. So we shuffled each lab’s departure dates 1,000 times, holding the lab and event counts fixed, and recomputed the effect under a within-lab placebo.
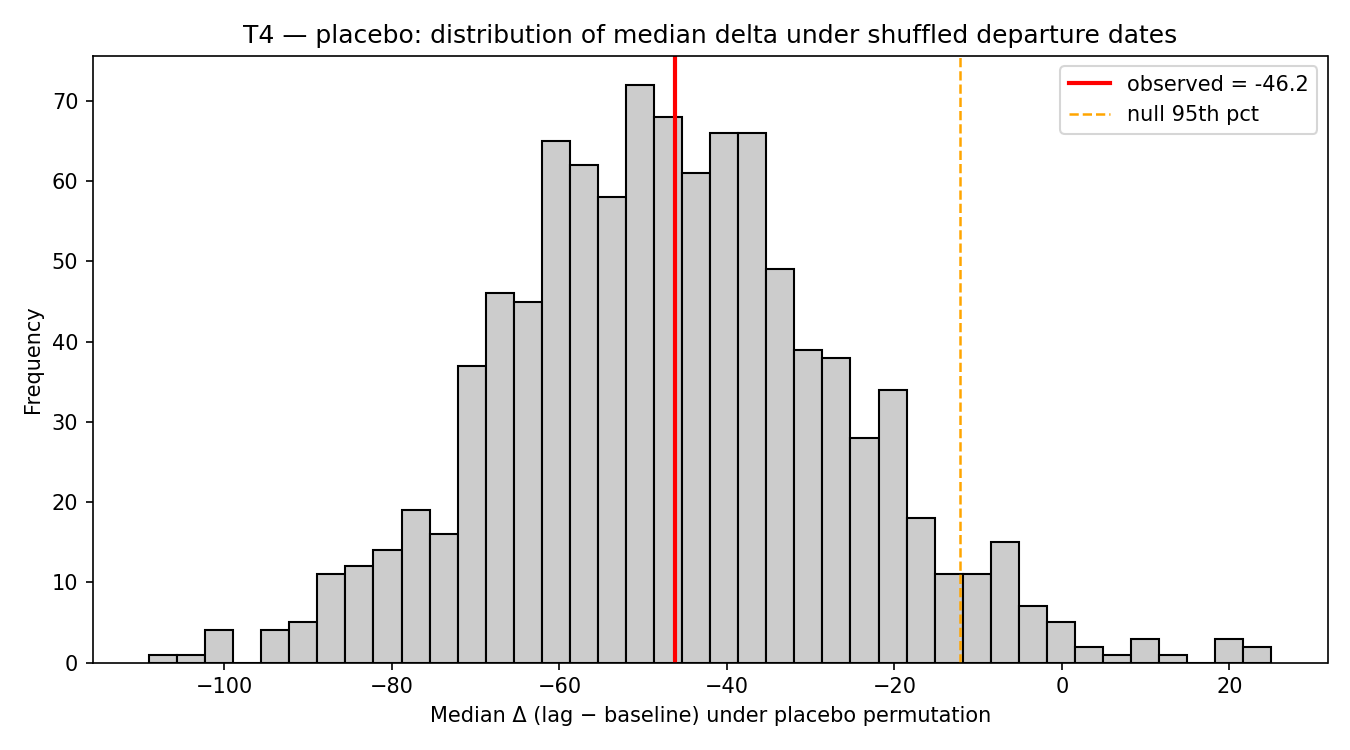
The observed effect sat in the middle of the null distribution. P = 0.49. The model release cadence result was indistinguishable from chance.
The cross-lab portability test failed too. Thirteen paired moves were measurable where a named researcher left one lab and joined another within twelve months. If individuals carry frontier productivity in a way that registers publicly, the origin lab should slow and the destination lab should speed up. Exactly one of thirteen moves landed in that hypothesis-consistent quadrant. A famous researcher joining an existing AI lab slowed their model release by 280 days at the median.
People matter. But the public model release cadence did not behave as if famous senior people were portable productivity engines. The data shows the inverse.
The tempting false positive
Model release cadence might be the wrong place to look. A model that ships three months after a resignation was already trained, red-teamed, productized, and probably half-launched internally before the resignation happened. The release can ship on time while the next research bet is already damaged.
That was the best rescue for the hypothesis, and we thought it might work.
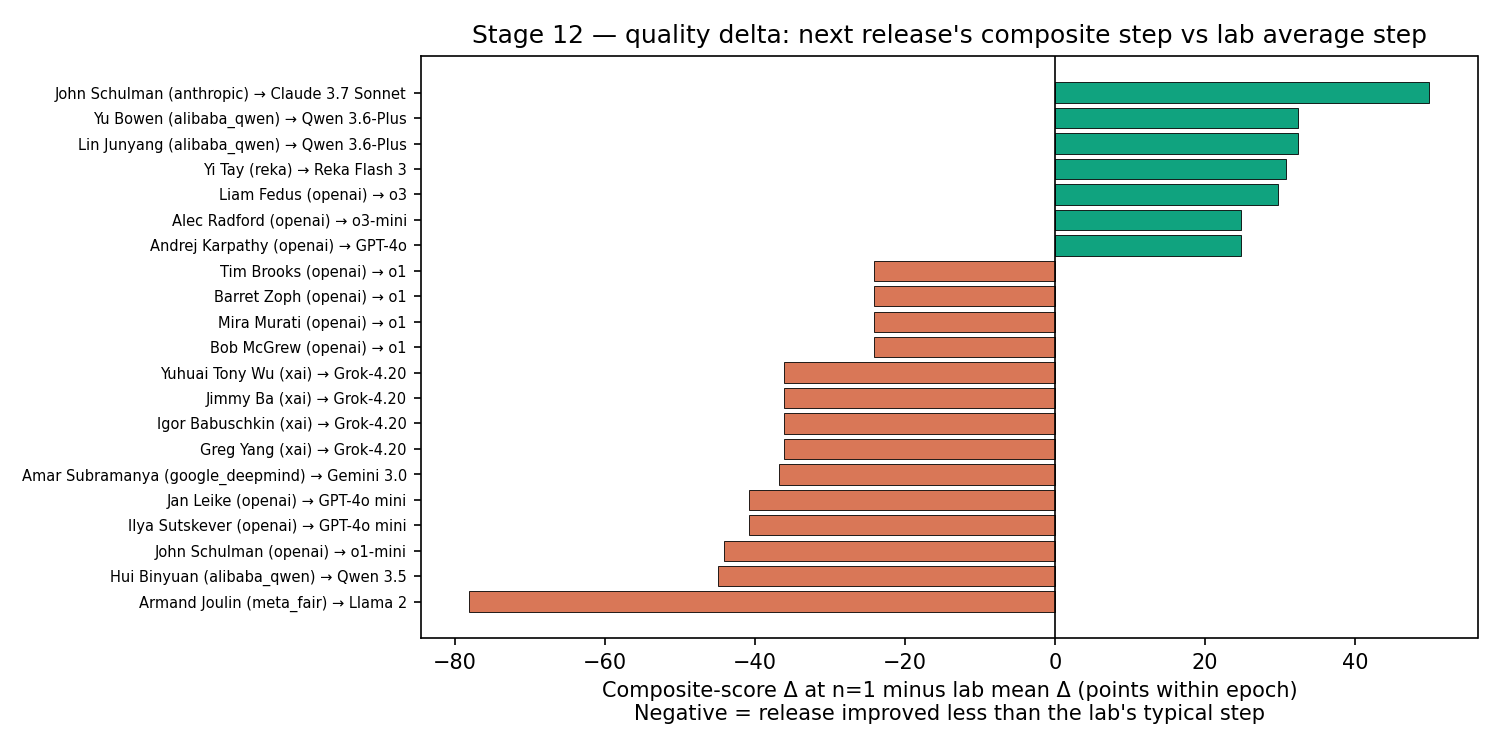
So we rebuilt the outcome around model quality instead of release dates. The benchmark corpus was split into five paradigm epochs, from the GPT-3 era through the agentic-2026 era. Within each epoch, each benchmark score was min-max normalized so contemporary results could be compared without pretending MMLU in 2021 and AIME in 2026 are the same object. Each release got a composite score from the epoch-appropriate benchmarks it reported.
Then we asked a sharper question: after a senior departure, was the next release’s composite-benchmark-score step smaller than that lab’s average step? Or put another way, did the new model get better by as much as that lab’s new models usually do?
Twenty-one events had enough data. Fourteen of them, 66.7%, were followed by below-lab-average composite benchmark steps. The median delta was negative 24 composite points (the models got worse at getting better)
For about a cup of coffee, that looked like the answer.
Then the placebo killed it.
We ran 1,000 within-lab date shuffles and recomputed the same next-release composite-step test. The observed negative 24-point median landed at the 23rd percentile of the null. One-tailed p = 0.235. Random dates inside the same labs produce a “brittleness” effect at least that large about one time in four.
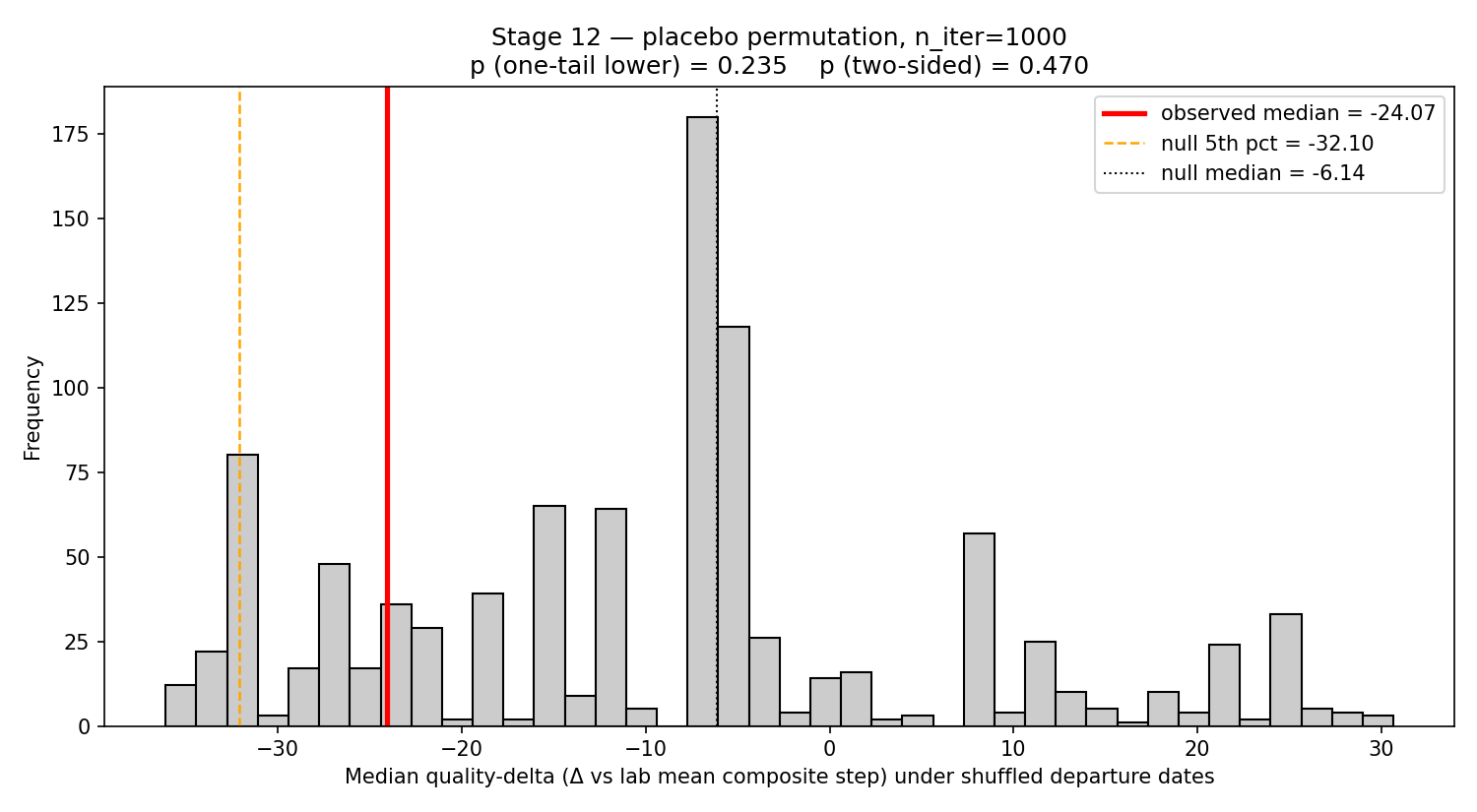
The mechanism is not mysterious. Lab release curves have structure. Big jumps often happen early in an epoch; smaller jumps follow near saturation. If personnel departures are more likely to occur around public milestones, a naive next-release test will mistake release-curve geometry for personnel damage.
The n=2 rescue failed even harder. I wondered if departures often happen at release milestones, so the next model is already in the pipe; the release after that should show the damage from key personnel loss. On the composite metric, 57.1% of events had the second release more depressed than the first.
But the placebo mean was 71.5%. Random dates produced the pattern more often than real personnel events did. The observed result sat in the lower tail of the null, with p = 0.96 against the brittleness direction.
Three placebos. Three nulls. Wrong, wrong and wrong.
The thing that looked like brittleness kept turning into release-pipeline structure.
The obvious counter-claim was only partly right
If big named researchers are not the lever that affects the AI labs, the next obvious answer is compute.
That story is also intuitive. Stargate is not just one of my favorite SciFi TV shows. Memphis Colossus hopefully did not add 100,000 H100s because xAI wanted a prettier CapEx line. Project Rainier and Google’s TPU fleets and Meta’s H100 clusters exist because the field believes scale still moves the frontier.
The first compute tests were surprisingly flat.
Compute at training-start had near-zero correlation with release cadence: Spearman rho = -0.12, p = 0.63. It had near-zero correlation with benchmark velocity: rho = +0.05, p = 0.87. It had almost comically zero correlation with composite-step delta: rho = +0.001, p = 1.00.
Then we caught a methodological problem that should have been obvious earlier.
The composite trajectory was mixing tiers. Anthropic ships Haiku, Sonnet, and Opus. OpenAI ships flagship, mini, Instant, and reasoning models. Meta ships 8B, 70B, and 405B-class models. Treating those as one continuous lab trajectory is nonsense; they should all come out of the same pretraining run. A Sonnet release is not the next point on an Opus line, it’s a fork somewhere in the process or a distillation. A 70B open-weight model is not the next point after an 8B model.
There was a second problem. Even inside a tier, a release’s improvement bundles the lab’s contribution with the field-wide tide: new RL recipes, better data curation, eval-driven post-training, and scaling refinements diffusing across the whole frontier. To isolate the lab effect, the comparison has to be same tier, same period, against peers.
So we rebuilt the analysis again. Each release was classified as flagship, mid, light, reasoning, or specialist. Specialist models were excluded from the general-purpose comparison. For each release, we computed same-tier velocity relative to the lab’s prior same-tier release, then subtracted the median same-tier peer velocity in a contemporaneous window.
That fixed the compute result.
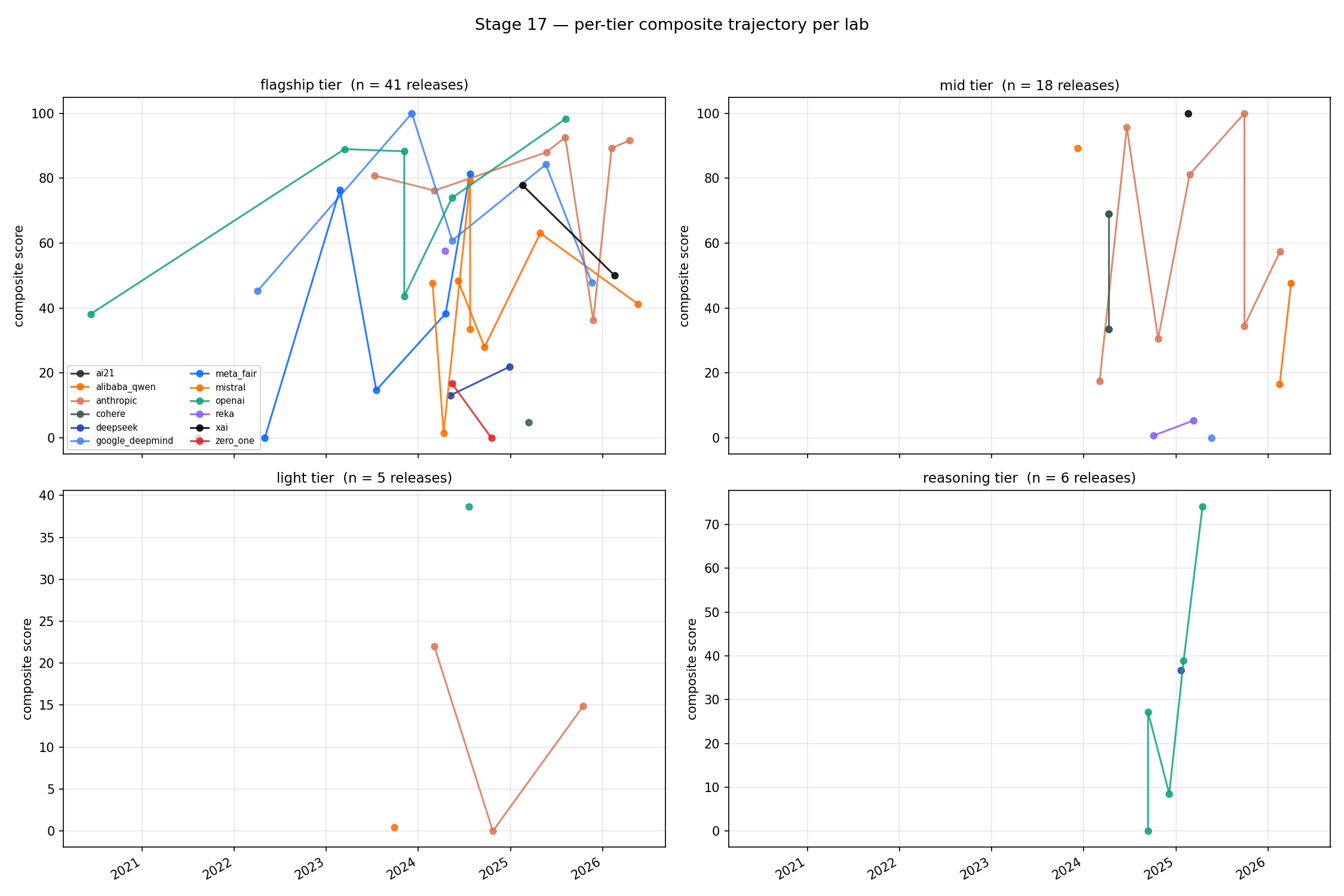
At the same tier, against same-period peers, compute showed up. Log compute at training-start correlated with above-peer same-tier outperformance at rho = +0.687, p = 0.028, n = 10. Compute per key person was also positive, though weaker: rho = +0.576, p = 0.082.
That is the first result in the study that made the simple scale story look right. Cross-tier compute comparisons were mostly measuring product-tier collisions. Same-tier peer comparisons recover the expected signal: if two labs are shipping comparable models into the same market window, the lab with more disclosed compute tends to outperform.
This is narrower than “compute explains everything.” It does not. The broad cross-sectional regression still explains almost nothing without lab fixed effects. But it is also narrower than “compute was a null.” The right comparison matters.
The personnel signal reversed
The tier-aware analysis did something more interesting. It found the first coherent personnel signal in the whole study, and it points opposite the brittleness story.
Within peer groups, senior departures correlated positively with above-peer same-tier model performance. Raw senior departures gave rho = +0.467, p = 0.044, n = 19. Departures per Price’s-Law key person gave rho = +0.506, p = 0.027.
Read that slowly. The labs with more senior departures built better models than their same-tier peers, not worse.
The arrivals side points the same way after allowing enough time for a senior hire to matter. Senior arrivals over a 24-month window correlated negatively with above-peer same-tier performance: rho = -0.441, p = 0.059. Arrival rate per key person was similar: rho = -0.421, p = 0.072. The labs with more senior arrivals built worse models than their same-tier peers.
That symmetry is the most useful result in the project. If one gambles in the stock market, the symmetry might make for a good bet as these labs become public companies whose shares move with famous researchers and then model releases.
Senior people leave labs that are outperforming their peer group, because those are the people everyone else wants to recruit. Senior people join labs that are underperforming their peer group, because those are the labs hiring to fix a problem. Personnel movement is not the cause of the visible performance change. It is the consequence of it.
This is still observational and small-n. We ran enough bivariate tests in the tier-aware stage that some p-values should cross by chance. Treat the exact coefficients as suggestive, not final until we have a few more years of natural experiments.
But the signs are coherent. Departures positive. Arrivals negative. Compute positive only when the tier comparison is correct. That is a much better model of the world than the original brittleness story.
The Meta exception
Every null result has a narrative case trying to climb out of it. Here the case is Meta.
The Llama team that wrote the original Llama paper mostly left for Mistral. Joelle Pineau left in May 2025. Yann LeCun announced his exit in November 2025. Llama 4 shipped in April 2025 and was widely read as disappointing. Llama 5 has not shipped. If you want the brittleness story to be true, Meta is where you point.
So we measured it separately.
Meta is the only still-operating frontier lab in the case-study set whose next-release window has clearly lapsed. Its phantom-release ratio is 2.07x: 413 days since Llama 4 against a 200-day historical median gap. Llama 5 is about seven months overdue as of May 23, 2026.
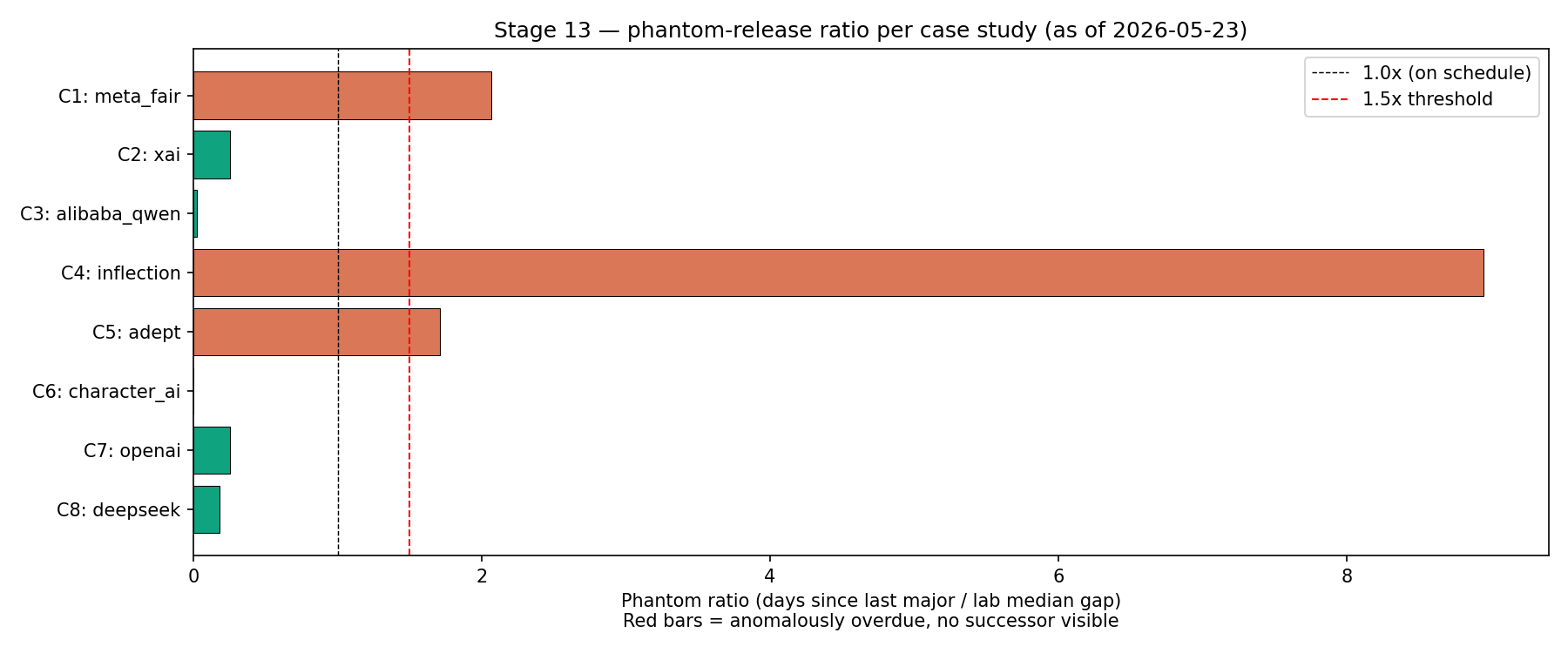
That part is real. Meta is a cadence exception.
But Meta is not a quality exception. Llama 4’s composite-step delta was negative 32 points relative to Meta’s historical mean, but Meta’s own release-to-release variance is huge: a 138-point range, with a standard deviation around 55. Llama 4 lands at roughly the twentieth percentile of Meta’s own history. One in five Meta releases is at least that small by ordinary Meta variance.
The narrative says Llama 4 proves personnel-driven quality collapse. The data says Llama 4 was a normal Meta release that landed into an unusually strong competitor window. Meta is late on Llama 5. Llama 4 was not separately anomalous on benchmark quality.
Those are different facts. They should not be fused into one story.
The “AI Labs don’t ship if they’re behind their competitors” theory also failed. xAI shipped Grok 4.3 even though it was 14 composite points below its closed Silicon Valley peer average. Meta was 56 composite points above its open-weight peer average when Llama 4 shipped, then went silent. The lab that shipped was behind peers. The lab that stopped was ahead of peers. xAI, as part of SpaceX, has an IPO coming which might have put a finger on their decision scale.
The Meta case remains worth watching. If Llama 5 slips another year and lands weak, it becomes a more serious single-lab brittleness candidate. As of this study, it is one cadence anomaly, not a population-level law.
What I now believe
My original hypothesis was wrong in a useful way.
Frontier labs are not just a few brilliant people and a pile of GPUs. They are release pipelines, training stacks, data engines, eval harnesses, post-training systems, safety reviews, product gates, procurement schedules, and hundreds or thousands of mid-career people whose names do not make the press.
Pull one name out and the pipeline keeps running.
Pull several names out and the pipeline usually still keeps running.
Add a large compute fleet and the next ship date does not automatically move, but at the same tier and against same-period peers, compute does help explain who outperforms. That is the part of the scale story that survived contact with the data.
The personnel story did not survive. Cadence did not slow. Benchmark improvement steps did not shrink. Price’s-Law adjustment did not uncover a hidden Celsius fueled cabal of key AI researchers. Cross-lab portability did not show researchers carrying public release velocity from one company to another. The only coherent personnel signal runs in the opposite direction: strong labs shed senior people because strong labs produce recruitable people; weaker labs hire senior people because they are trying to catch up.
This matters because the mental model drives the lever people reach for. If frontier labs were brittle around a few named researchers, personnel pressure would be a strategic lever. Immigration pressure, regulator scrutiny, targeted recruiting, leadership disruption, and public pressure on individual researchers would all have obvious multi-quarter effects.
The data does not support that model. When Meta tried to attract top AI researchers with outlandishly large stock options, the data says it was neither going to make Meta better or their competition worse.
It says frontier labs are institutionally robust. The center of gravity is not the masthead. It is not even visible in most public data. In the broad cross-section, personnel and compute together explain less than 1% of composite-step variance without lab fixed effects. With lab fixed effects, explanatory power rises to about 15%. Which lab a release comes from tells you more than which senior people left, which senior people joined, or how much compute had been disclosed.
Different labs are different. The public variables we measured do not explain why.
That is the honest finding. The brittleness in AI Labs we expected to find was not there. The strongest visible lever, compute, only becomes clear after comparing the right products against the right peers and does somewhat support OpenAI’s strategy to buy up the compute market to depress their competitors compute. But the personnel flow points backward from performance, not forward into it.
All models are wrong. This one was wrong quickly enough to become useful.
The primary cadence tests were pre-registered before analysis to preclude confirmation bias. The strongest apparent quality signals were checked against within-lab placebo shuffles and failed. The tier-aware peer-relative analysis is suggestive and we wish could be replicated with a larger independent personnel dataset and better private compute estimates; neither of which are public.