The Coming Collapse of the Software Monoculture
The real implication of autonomous cyber reasoning systems is not faster bug patching, it is disposable code and durable product behavior.

A friend made an observation after DARPA’s 2025 AI Cyber Challenge that has stuck with me.
His read was that almost everyone walked away thinking some version of: “AI is going to make my existing cyber tools better.” Better fuzzers. Better source code analysis. Better patch generation. Better triage. Better copilots.
A much smaller group seemed to walk away with the more important conclusion: whole classes of problems are ceasing to be problems.
That distinction matters.
Most software and cyber workflows were designed around old constraints: human attention, human core working hours, human code comprehension, brittle tooling, slow QA cycles, expensive reverse engineering, and slow deployment. If those constraints change, then simply “adding AI” to the existing workflow is the least competitive thing we can do.
The real question is not: How do we make today’s workflow faster?
The real question is: Which parts of the workflow should stop existing?
When we ran DARPA’s Cyber Grand Challenge (CGC) a decade ago it was intended to force the integration of technologies into completely automated workflows. But the state of the art constrained it to working on toy sized programs. I didn’t run the AI Cyber Challenge (AIxCC) but I did run the organization that ran AIxCC. AIxCC was intended to leverage AI to scale fully automated workflows to real world sized software.
The recent AI breakthroughs in vulnerability discovery does not mean “AI is going to hack the planet” or that “we need to discover and patch all of the vulnerabilities before the models become public.” It means something more specific and more important: autonomous systems are now good enough that we need to rethink where the durable value in software actually lives, not slap patches over software that was valuable yesterday.
The code is becoming less important than the product
The compound vibe moving through the software community is deceptively simple:
Forget that the code exists. Do not forget that the product exists.
That sounds wrong at first. Code has been the center of gravity for the Western economic system for a decade or two. We hire people to write it, review it, test it, secure it, deploy it, document it, and maintain it. The codebase is treated as the asset.
But that assumption is becoming weaker.
For many software products, the durable asset is not the code. It is the behavior of the product. It is the requirements. It is the user workflows. It is the production telemetry. It is the business logic. It is the integration surface. It is the institutional knowledge encoded in how the system is actually used.
The code is increasingly just one implementation of that behavior.
Once AI can generate, test, patch, refactor, and deploy software with enough reliability, the codebase starts to look less like a permanent asset and more like a temporary artifact.
That has major implications.
The old workflow was organized around human bottlenecks
Consider the standard software lifecycle:
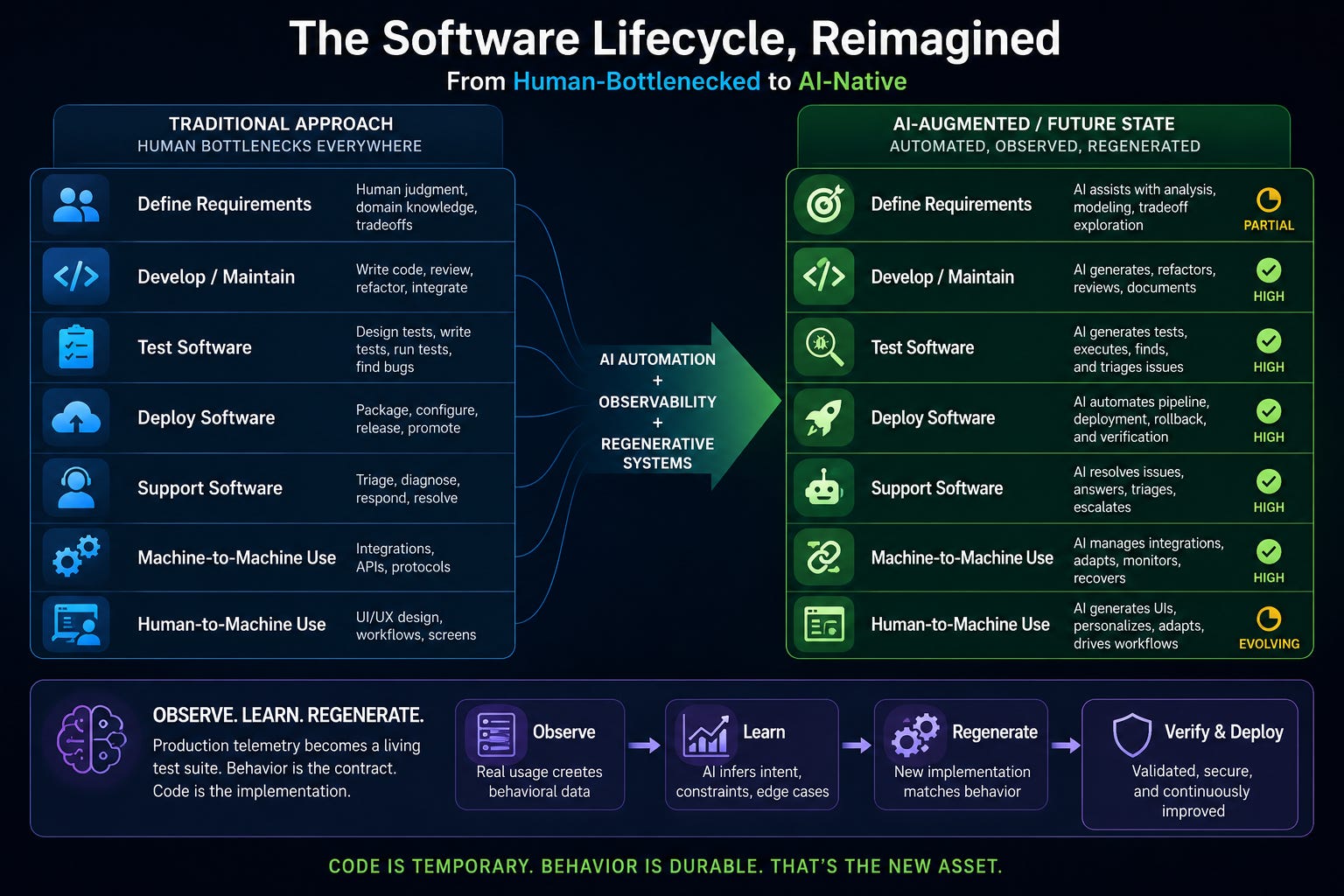
The weak point is not code generation anymore. The weak point is specification.
AI is already good enough to produce a lot of software. It is much less reliable at knowing what software should exist, what tradeoffs matter, which edge cases are business-critical, which workflows are sacred, and which “requirements” are actually accidental artifacts of an old system.
That means product management, domain modeling, integration, observability, and requirements capture become more important, not less.
The value moves up the stack.
The near future: regenerate the enterprise stack
I think we are a significant integration exercise away from something like this:
An AI system reverse engineers an enterprise’s existing software. It instruments that software so production usage creates a de facto behavioral test suite. It observes real workflows from the inside: API calls, user paths, data transformations, error states, permission checks, and integration dependencies. It then generates a replacement stack, tests that stack against the observed behavior, iterates until it matches the required functionality, and deploys the replacement. And it does again and again: when a user calls into the help desk with a verifiable issue that the AI adds, when the organization needs a new feature that is otherwise blocking a sale, or when a partial enterprise outage needs to be worked around in real time.
That sounds aggressive, but it is not science fiction. It is a composition of technologies that already exist in partial form: reverse engineering, program synthesis, code generation, fuzzing, tracing, regression testing, observability, deployment automation, and AI-assisted debugging.
The hard part is not imagining the pieces.
The hard part is integrating them into a system that enterprises (and lawyers) can trust. That was the whole point of Cyber Grand Challenge that we never told you. That was the whole point of the AI Cyber Challenge that has been missed as we are distracted by the shiny vulnerabilities.
This is where “vibe coding” is both a toy and a signal. The toy version is a person prompting an LLM into producing a small application. The serious version is a system that can re-create software from observed behavior, instrument the legacy system, generate a test corpus from production use, and then lay down a new implementation; at speed and scale.
That is the real software automation frontier.
Not “write me a React app.”
Instead: infer the product from reality and regenerate the code.
The defensive cyber implication
Now apply this to cyber defense.
Today, offense and defense are racing over the same software.
Offense searches for access methodologies, some of which are vulnerabilities. Defense searches for bugs, some of which are vulnerabilities, and then tries to patch them before exploitation becomes operationally meaningful.
This race is structurally bad for defenders.
Modern society has a relative lack of software diversity. Huge numbers of enterprises depend on the same open-source projects, the same commercial products, the same SaaS providers, the same frameworks, the same libraries, and the same deployment patterns.
That gives offense scale.
An attacker can concentrate resources against a small number of high-leverage targets. Defenders, meanwhile, have to protect everything they run, including software they did not write, do not understand deeply, cannot easily modify, and cannot replace quickly.
That is the familiar asymmetry.
But now imagine a different world.
An enterprise’s software is bespoke. Not bespoke in the old, expensive, artisanal sense. Bespoke because AI can generate and regenerate software cheaply. The enterprise still has the same product behavior, but the implementation is specific to that enterprise, that environment, that workflow, that deployment context, and that moment in time.
Offense can no longer assume that analyzing one common software package gives access to thousands of targets.
Offense has to analyze the target-specific implementation.
And if that implementation changes more frequently than the attacker can acquire, study, operationalize, and exploit it, the defender has changed the game.
This is not just patching. It is not just moving-target defense. It is software diversity at generation speed.
The offensive side also automates
Of course, offense gets AI too.
The offensive workflow is also automatable:
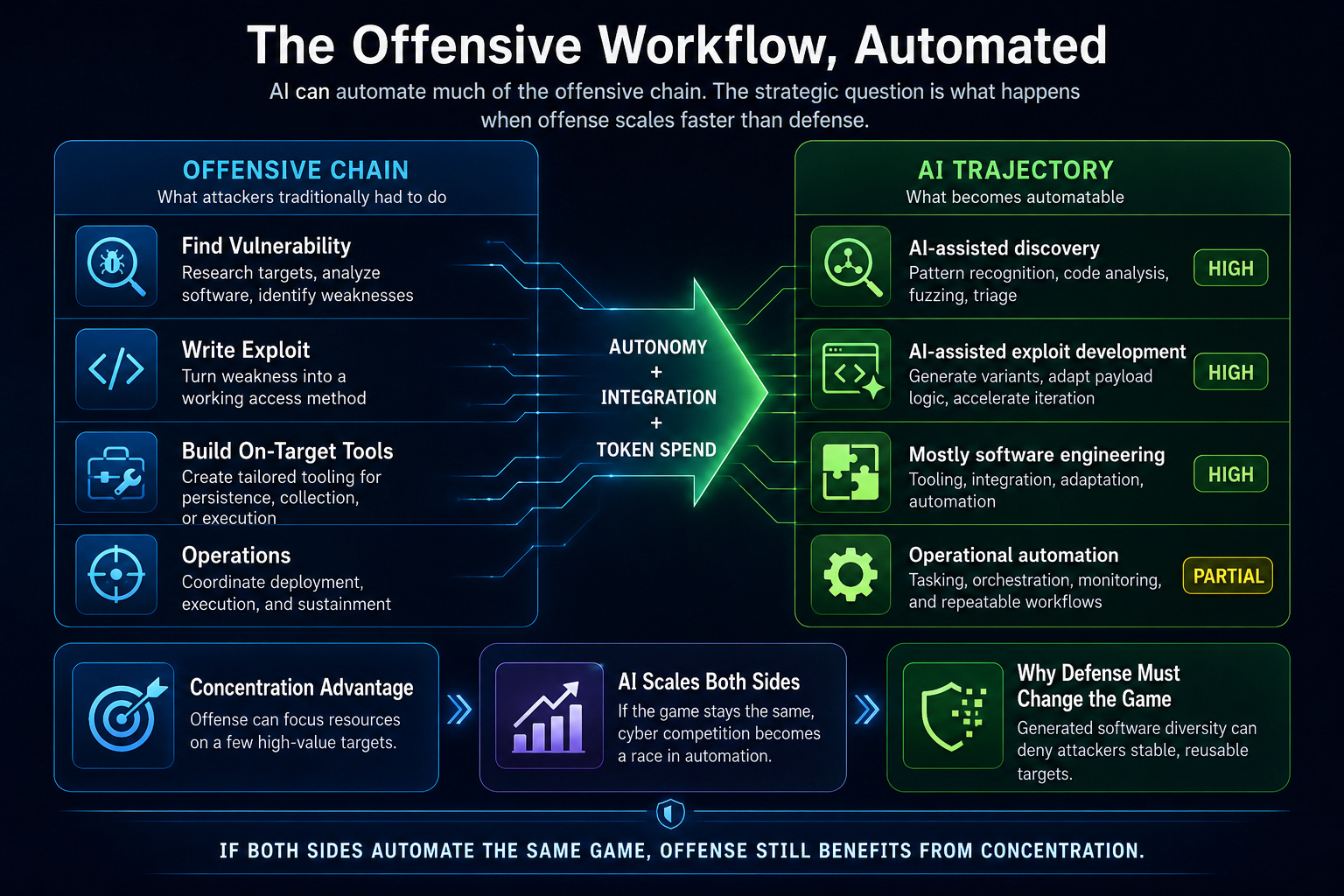
So if we leave the structure of the game unchanged, the future becomes brutally simple: cyber conflict turns into a contest over who can spend more tokens, integrate better tooling, and run more autonomous analysis.
That is not a good defensive end state.
It preserves the same basic asymmetry we already have. Offense can focus. Defense has to cover the world.
If AI only accelerates both sides inside the current software monoculture, offense remains structurally advantaged.
The better defensive strategy: generated diversity
The defensive opportunity is to stop presenting the same target to every attacker.
The future of serious cyber defense may be bespoke generated software that changes faster than it can be exposed to meaningful offensive analysis.
That does not mean randomizing code for the sake of randomization; offense defeated that defensive philosophy two decades ago. It means generating functionally equivalent software that preserves required product behavior while changing implementation details, dependency structure, internal interfaces, control flow, deployment topology, and other properties that attackers rely on for scalable exploitation.
Maybe I should instead call it constantly self-improving code.
In that world, the defender’s durable asset is not a static codebase.
The durable assets are:
the product requirements;
the behavioral test suite;
the production telemetry;
the data model;
the business logic;
the deployment policy;
the security invariants;
and the ability to regenerate.
Code becomes disposable.
Behavior becomes durable.
The future target is business logic
If that world emerges, offense does not disappear. It moves.
Attackers will spend less time searching for reusable vulnerabilities in common software and more time attacking business logic, process assumptions, identity flows, authorization boundaries, data semantics, organizational dependencies, and human decision loops.
That is the natural consequence of generated software diversity.
If the implementation layer becomes nondeterministic from the attacker’s perspective, the attacker moves to the layers that remain stable.
That means defenders should not get complacent. Bespoke generated software is not a silver bullet. It can generate bespoke bugs. It can preserve flawed requirements. It can encode bad assumptions. It can create new classes of integration failure. It can make systems harder to reason about if the behavioral test corpus is incomplete.
The strategy only works if the enterprise can specify, observe, test, regenerate, and verify the product better than the attacker can analyze it.
That is a high bar.
But it is a fundamentally different bar from “patch faster.”
Web++ means forgetting the code, not the product
The Web++ future is not that software disappears.
The product still matters. The workflow still matters. The user still matters. The business process still matters. The security invariant still matters.
What disappears is the assumption that the codebase is the sacred object.
For decades, we treated code as the thing to protect, maintain, audit, and preserve. That made sense when code was expensive to produce and hard to replace.
But when code can be regenerated, the center of gravity shifts.
The winning organizations will not be the ones that merely add AI to their existing software development lifecycle (SDLC). They will be the ones that redesign the organizational lifecycle around the premise that code is a temporary implementation of product behavior.
That is the cyber defense opportunity.
Do not just use AI to patch the old world faster.
Use AI to make the old world the wrong target.