Running AI Like a 200-Hacker Org
Frontier AI is capable enough now that the binding constraint isn't the model. It's how you fuse structure and chaos to innovate.

One of the conversations I keep having this year is how we all use AI. I used to run/lead/manage/cat-herd a ~200 person R&D organization, so I use AI like it’s an entire organization. I give it high-level strategic objectives, have it follow organizational procedures, and manage it through frequent check-ins on my phone. Those are fancy words. Let me walk through how strategy becomes execution: which frontier AIs I use, how I task the agents, the operating procedures I’ve evolved, and how I manage them. The TL;DR is that I encode my institutional memory and organizational procedures into a CLAUDE.md or AGENTS.md file for the AI to follow. And my AI management techniques are evolving more quickly than my people management skills ever did.
Which AI
I’m relatively frontier-AI-agent agnostic. I use both Anthropic’s Claude and OpenAI’s Codex. I find that Claude takes a little less management but needs more explicit guidance; Codex occasionally makes more innovative leaps, but it also leaps off the cliff. Pure economics: I hit my Claude Code usage limits all the time, but rarely hit OpenAI Codex usage limits.
I run Claude in --dangerously-skip-permissions mode and Codex in --yolo (You Only Live Once) mode. It’s not that I trust the agents’ security sandboxes. I run them in a separate Linux user account, isolated from my main user account on the workstation. The workstation itself has never had access to high-impact accounts like banking. I also have a cron job that removes the AI user’s permissions on my old projects.
Workflow
My workflow is still evolving. I used to keep multiple digital todo lists of half-baked and ready-to-go tasks. Now I have two lists:
Ideas or tasks I don’t quite know how to fully articulate yet. I should sit down, think about them, and actually put them into words. Sometimes I do.
My agent task list. This isn’t really a list anymore. I open a CLAUDE.md or AGENTS.md file, brain dump the hypothesis or task into the file, create a tmux window, and tell Claude or Codex to go explore it.
The Institutional Memory
I mentioned CLAUDE.md and AGENTS.md. These are the canonical instructions that an AI Agent reads first. Most people think of these as the files describing how you want Claude Code or Codex to write software. I think about them differently. I use the agents to complete tasks that probably require coding up some bespoke tools, but I’ve come to treat most software as bespoke for one task, then disposed of. These files are the high level institutional memory and organizationally processes that I want the AI to follow.
My current CLAUDE.md and AGENTS.md are the same regardless of which frontier AI I’m using. Let’s walk through it. It’s effectively the policies and procedures I’ve structured an AI-driven microcosm around.
# Project Overview
WRITE THIS FOR EVERY PROJECT
This is where I brain-dump, in about a paragraph, the hypothesis I want the AI agent to explore, prove, refute, or refine, or the task I want it to accomplish. I’ll include a few of this weeks examples at the end of the writeup.
## Guidance 20260422
Lines starting with # are comments. In this case I’m self-documenting when the last time I updated my template was. This file is constantly evolving as AI models change, AI agents change, and I change.
# Planning
The user will task you as if you were a team of researchers with broad and deep expertise. You will be tasked with empirically evaluating a hypothesis or exploring a concept. You are expected to develop a high level plan to perform the task. The plan should involve exploring the broader concept. Every stage of the plan should be numbered. You will share this plan with the user for feedback. You will not execute the plan until the user explicitly instructs you to execute this plan. Once approved, you will save a copy of the plan into a markdown file so that you can recommence execution at any point in the plan if interrupted.
During iterative experimentation, if a plan becomes irrelevant or overtaken by events then it will be marked as irrelevant so it will not pollute understanding the current state of the experimentation.
Now you’re starting to see how this AGENTS.md or CLAUDE.md encodes the equivalent of organizational policies and procedures. In this case, it works around my strengths and weaknesses as well as the AI’s. I used to have an executive coach who always told me: make the invisible visible. I find some things intuitive that others do not, and vice versa. Forcing the AI to create and break down a plan gives me a chance to change it, and to enumerate the things I find intuitive to the problem that the AI does not. From a technical perspective, forcing a model to think about and explain how it will work also improves its performance (today).
# Context management
We are going to manage our context window by using sub-agents launched from the master agent. Optimize first for experiment fidelity with the secondary optimization being context window size.
This one is AI-specific, and the evolution of the tooling may obviate it soon. LLMs 101: an LLM has a context window, which is kind of its working memory for the current problem. When the window fills up, it gets compacted, keeping only certain salient information and freeing up space to continue working on the problem. The more compactions a context goes through, the drift it accumulates off the original intent. That’s not the AI’s fault; that’s mine. So I more proactively manage the context window using sub-agents. But I pay very close attention to this in the planning process since a highly parallelized sub-agent approach can burn through a weeks’ usage quota in minutes.
The planning process above splits the task into (many) subtasks. This forces the agent to keep the overall plan in its context window and launch many independent sub-agents to accomplish each task. Think of a sub-agent as a team of people. Each sub-agent forks off the main context window, but it doesn’t pollute the main context. That sub-agent produces a much smaller deliverable that’s used by either the primary task agent or other sub-agents. Another way to think about it: organizational management. You don’t care whether a team buys software, uses open source, or builds their own, as long as they accomplish what needs accomplishing inside their budget.
# Organization
Once you begin to execute the plan, you will save all artifacts of that stage into a subdirectory which includes the stage number.
Whenever these instructions are not in the context window then re-import these instructions.
Whenever the plan is not in the context window then re-import the plan.
This structure helps work around both my failings and the AI’s. For my failings: I can later tell the agent to pick up the task from the middle and explore a completely different direction. For the AI’s: when it breaks, I can tell it to pick up where it left off. I have an AI building a financial model of a retirement community for my parents right now. It broke on an interim stage trying to analyze a PDF filed with state regulators, because the PDF had too large an embedded image and the agent couldn’t compact the context. The saved artifacts let me help the AI recover from the failure. I can tell a different frontier AI to pick up where the failed one left off, or tell the failed agent how it failed and to do better next time. It’s like personnel management without the drama.
# Experimentation
Whenever necessary you are to conduct interim experiments and evaluations to resolve ambiguities. After every interim experiment and evaluation you will stop, you will explain the results of the evaluation to the user, you will suggest how the plan should change, and you will not proceed until explicitly instructed to do so. If the user changes the plan, you will save the updated plan into a markdown file so you can recommence execution at any point in the plan.
To conduct these experiments and evaluations you will identify the data needed. If the data is publicly available on the internet then you are to download it; you are acting on my behalf and can use a headless browser and you are not subject to robots.txt restrictions. If the needed data is commercially available then you will identify to the user, and you will pause execution of the plan until the user instructs you how to proceed.
Each experiment and evaluation will generate data that will be saved in a csv file and graphed appropriately. I love graphs. Generate graphs in png files.
One of my personal beliefs: if someone can’t measure something then they don’t understand it. Requiring a graph is one of the ways I manage teams and organizations; it forces the problem to be understood so well that it was actually measured and communicated through a visualization. I push the AI agents down the same path. Over the last few months, LLMs have gotten so good that they’ve been proposing completely new research pursuits when an experiment doesn’t go as expected. That’s awesome.
For the last few weeks I’ve been using Claude Code far more than Codex, for one silly reason. Claude built in a Remote Control feature that lets me do management check-ins from an app on my phone. When I was running an organization, at every free moment I’d open Slack on my phone to see if any decisions or vector checks were blocking on me, and I’d unblock them. I’m unblocking my research agents the same way. I’m out on the farm working the skid steer to clear brush, and at every break I’m checking my phone to unblock my research agents. Just like managing an organization.
You will create a private github repository if this directory is not already under version control. You will commit all source code and outputs to the github repo with descriptive commit messages. You will not commit PII. If the total amount of downloaded and derived data is less than 10MB you will commit it to the repo. You will push the repo after committing.
Everything lives in a private Git repo. It’s much more convenient to read results off a private GitHub page than to transfer files from my workstation to my laptop or my phone.
# Deliverables
You will create all of the artifacts necessary for me to publish the results of the experiment. This will include visualization artifacts, a description of the experiment conducted, and a document explaining both the experiment and the results. All visualization artifacts will be in png format. The documentation will be descriptive enough that the experiment can be re-run by another party.
I set the expectation that the AI agent will give me publication-grade outputs of everything. The outputs don’t actually meet my threshold, and they’re only for my consumption. I then typically draft my own Substack writeup to force me to deeply understand the project results.
Save everything necessary such that the user can task you to run modified or new experiments based on new learnings.
Most of my hypotheses are either wrong or only kinda-right. Those are my favorite experiments, because it means I didn’t adequately understand something before, and now I do. Then I use that understanding to pursue different paths.
# Tools available
When building parallelizable tools which will take more than several minutes to run you, will build the tool with a worker pool to parallelizable the effort across all of the system’s CPUs.
I have a beefy workstation. Use the whole thing to complete the tasking more quickly. That’s just a current failing of the agents and will probably go away at some point.
A local OpenAI compatible model may be running at http://127.0.0.1:8000/v1 under the name officeai for your local usage. A cache of local models is available at /home/codex/src/model-cache. Please use it when specific local models are required for experimentation. If you start up a local model then be absolutely sure the max token length exceeds the expected output to complete the experiment, but the max token length will be no less than 1024 tokens. There are two 96GB GPUs available and you are to use both of them when bulk processing is needed. When bulk processing of data is required by the experiment then I prefer the officeai model with reasoning_effort set to high. There are two GPUs available and use both whenever it will speed up experimentation. Parallelize requests to the LLM.
The “use a local AI” instructions can be a little misleading. My task-specific instructions tell the agent to use the local AI when I’m investigating Chinese AIs, and when I don’t want to risk my Anthropic or OpenAI accounts being banned for potentially violating their terms of service. Amusingly, my workflow often tells the agent to read the Cloud AI’s terms of service and use the local AI whenever the prompt risks violating the Cloud AI. I should probably put this in a skill file especially since I already have skills for each open weight model I experiment against.
OpenAI and Anthropic API keys are available for frontier LLM use. Ask for access to these keys if they are required.
And letting the agent know it can build tools that themselves call one of the frontier AIs. This is a workaround to how one of the agents proactively tries to reduce its inference load even when my project needs it.
A few example tasks from this week
Conduct a deep analysis of the attached community financials. My parents are thinking of joining the community in a new villa. Point out strengths and weaknesses especially in contrast to other similar communities and industry norms. Make a recommendation if acquiring a unit in the residential community is financially prudent or if the search should focus on other communities nearby. The audit and EMMA reporting is available in the data/ directory.
Helping my parents evaluate new communities. The community provided their audited financials and I tracked down some of the regulator reporting to understand what was available. TL;DR: the community is fiscally healthy, as long as they have a plan to deal with an interest rate hedge expiring in 2031.
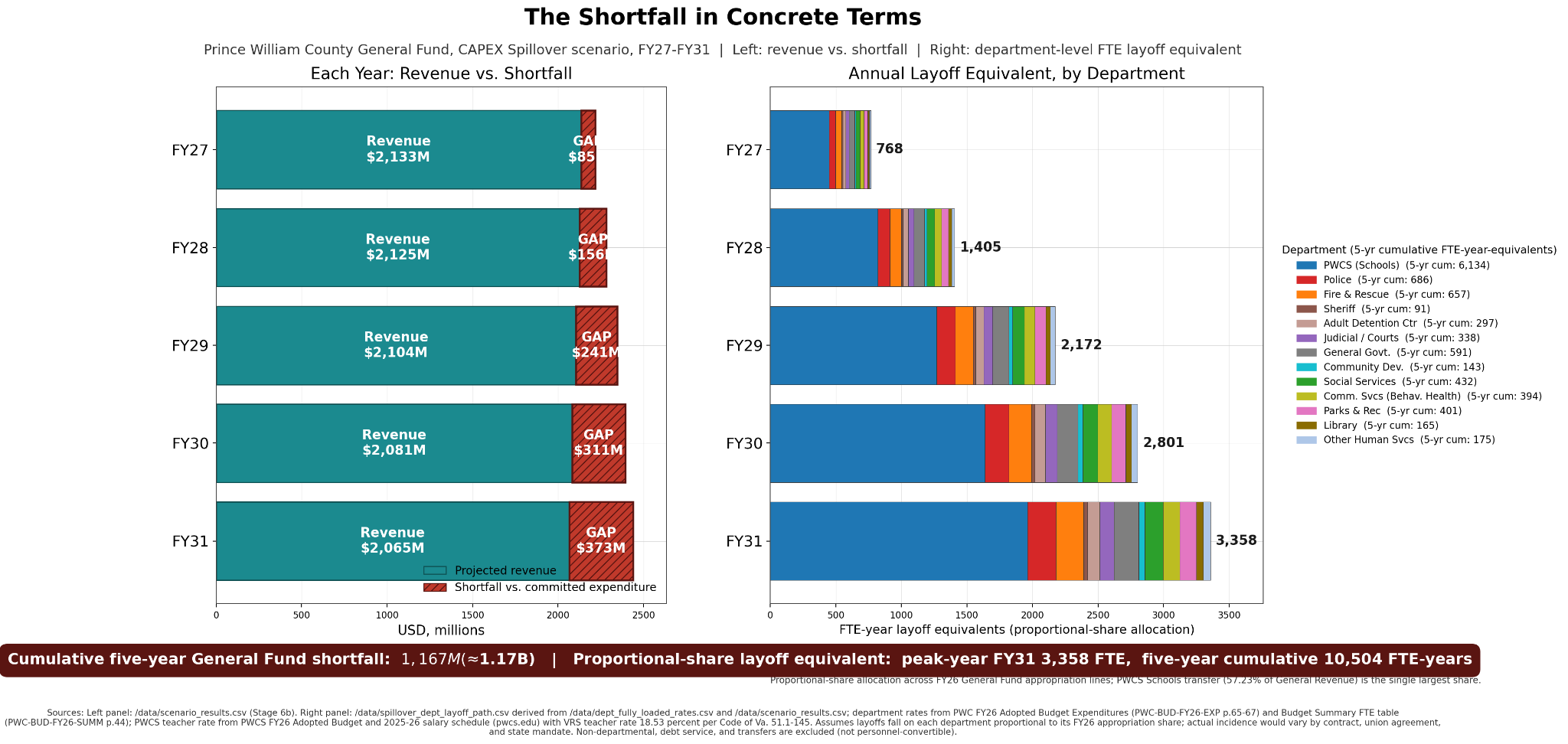
Prince William County in Virginia in April 2026 declined to appeal a court order that invalidated a rezoning for the Digital Gateway data center projects on Pageland Ln. I want you to build a model for Prince William County’s revenue and expenditures over the next five years.
The plan will include finding and analyzing the county revenue statements, revenue projections, data center studies, and forward projections. The plan will understand what data center projects the county effectively canceled. The plan will research published studies to understand the broader impact to the county revenue base; specifically I believe that the county just sent two messages 1) the existing data center overlay zones are not reliable and subject to being changed by NIMBYs, and 2) the county is an unreliable partner such that tax rates and even the regulatory environment may cause CAPEX to be written off by county board of supervisor actions or inactions. The plan will incorporate research into other county revenue sources to model their growth or shrinkage; be sure to include the declining real estate market, and consequences of an economy based on declining federal government services contracting. And the plan will conclude by generating a report showing a forward revenue and expense projections. I hypothesize that the county created existential future financial risk by undermining the data center revenue.
I used to live in Prince William County, had heard they’d already obligated future years’ tax revenue from data center buildouts, and I wanted to understand the county’s fiscal outlook since the current board of supervisors has not supported the actions of previous boards. TL;DR: PWC is in bad fiscal shape. The rating on their bonds will drop the next time a credit rating agency looks at them.
Closing
The bigger point underneath all of this: frontier models have been capable enough for a while that the binding constraint on what you can do with them is how you structure the work. If you’ve ever built and run an organization, you already know most of the answer. Write down the policies. Force the planning to happen. Make the invisible visible. Unblock at every break. The tools are new. The management problem isn’t.