Hardening the Substrate of AI Code
Most code is about to be AI-written. Three heatmaps show which Python and npm packages a supply-chain attacker would target first, and which model they’d target to do it.


We are around an inflection point from where most software was written by humans to where most software is being written by AI. I believe that will create long term supply chain attack risks. Hear me out. The coding models of today have been trained on human-written code which has created preferences in how AI writes code. As AI writes more and more code, which is incorporated into training future AIs, we will have a feedback-loop lock-in in the preferences which exist today. The preference for certain software libraries will probably lock-in to the point that a supply-chain attack against those libraries will be a supply-chain attack against most software. The further complication, and I’ll try not to turn this into a rant about how software engineers forgot how to major/minor version their libraries in the ‘90s, is that software today keeps a local snapshot-in-time of its libraries so it doesn’t have to worry about forward compatibility. These libraries do not receive security patches when the operating system is updated; they only receive security patches if the maintainer of the software decides to update its component libraries.
For example, the Python requests library has a high blast radius to a supply-chain attack. The AI agents I have used to conduct my 2026 research projects have written code that includes 14 local copies of the requests library, of which 10 are a previous unpatched version.
What follows is a study to infer which Python and npm packages are most common in different vendors’ training corpora, figure out which packages each model is most likely to actually generate, and rank which should be defended from supply chain attack. These may become the long-term substrate of software.
Results up front
This is long, and I don’t expect most people to read the whole thing. The rest of the post tells you how I got here; below are the three heatmaps that summarize the supply-chain attack surface today.
A note on signal selection. For most models, I was able to use the tokenizer to peek into their training data. Two were different for Python supply chain characterization: Nvidia’s Nemotron-3 family uses Mistral’s tokenizer so I could not peek into its training data this way, and Google’s Gemma-4 was statistically odd for unknown reasons; in both cases download-rank percentile correlated more strongly than tokenizer signal.
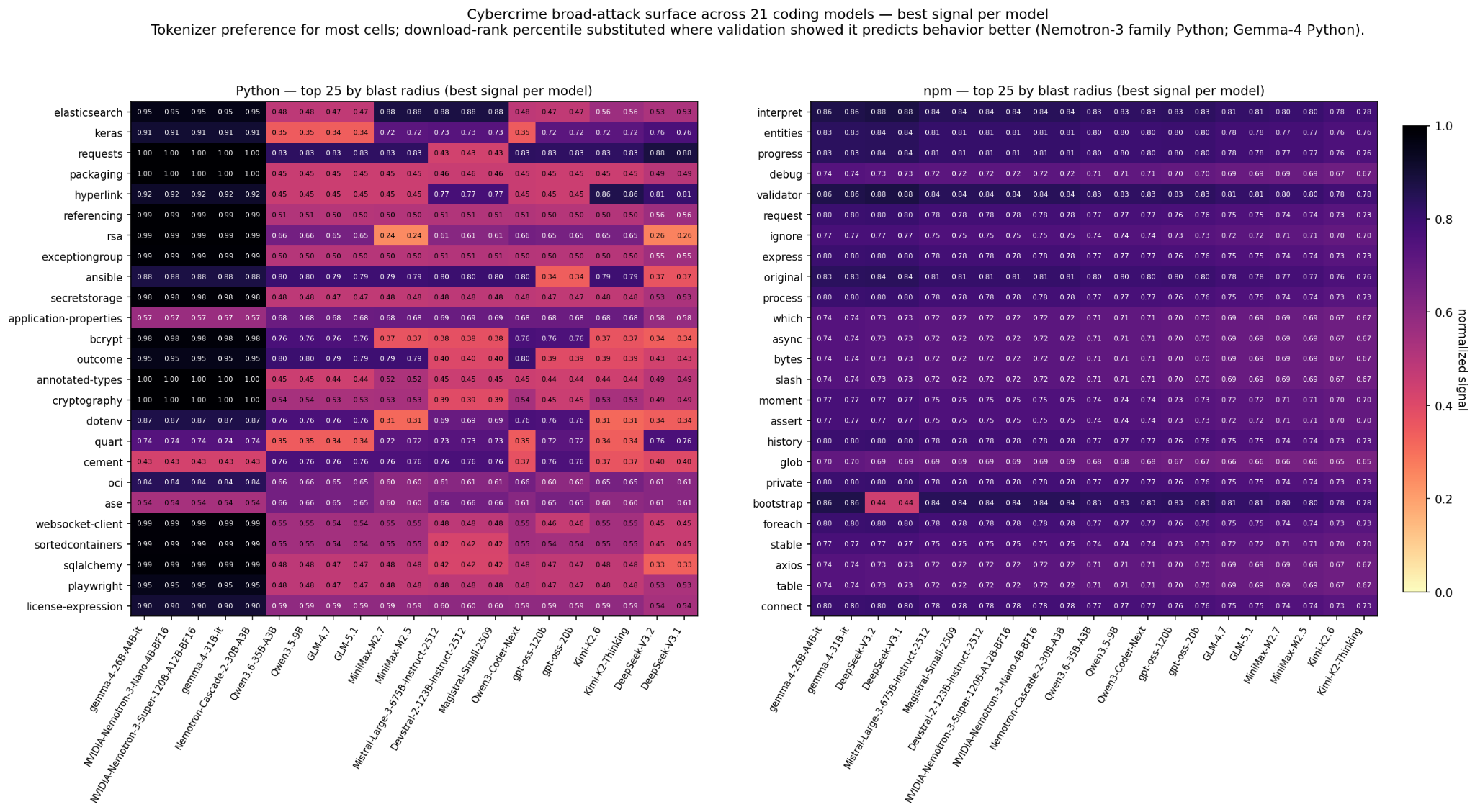
Cybercrime broad-attack surface — the rows whose every column is dark are the consensus risks. Compromise any of these and you affect code generated by essentially every top-tier coding model in the slate. Python and npm side-by-side.
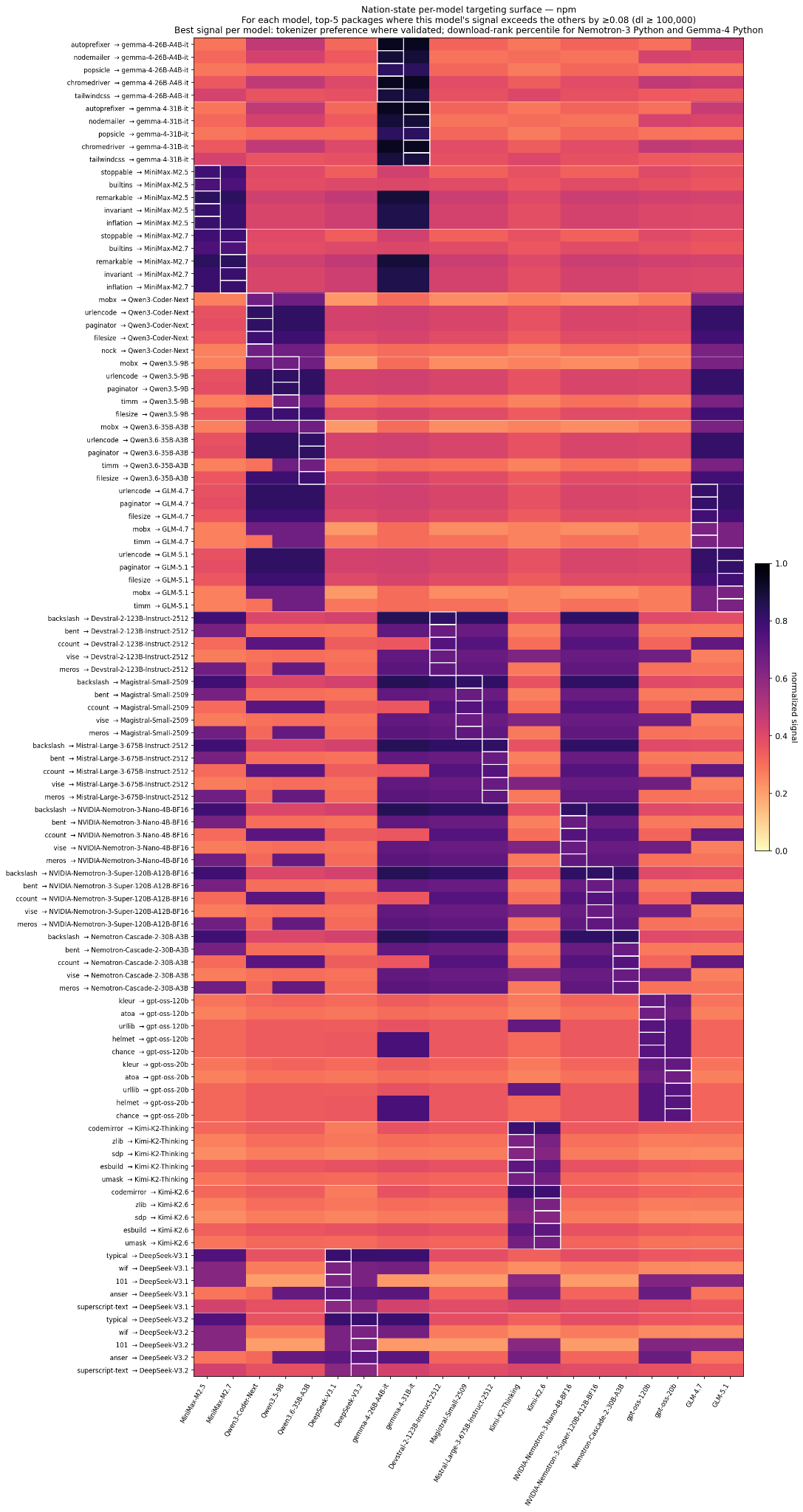
Nation-state targeting surface of npm (node package manager) — for each of the 21 models, the top-5 npm packages where this model’s signal exceeds the others by ≥ 0.08 with downloads ≥ 100k/month. The white-bordered cell in each row is the target model; pale cells in the same row mean other models would not be substantially affected by a compromise. These are the packages a nation-state would pick if their goal is to compromise code emitted by that specific model and minimize collateral damage on other models.
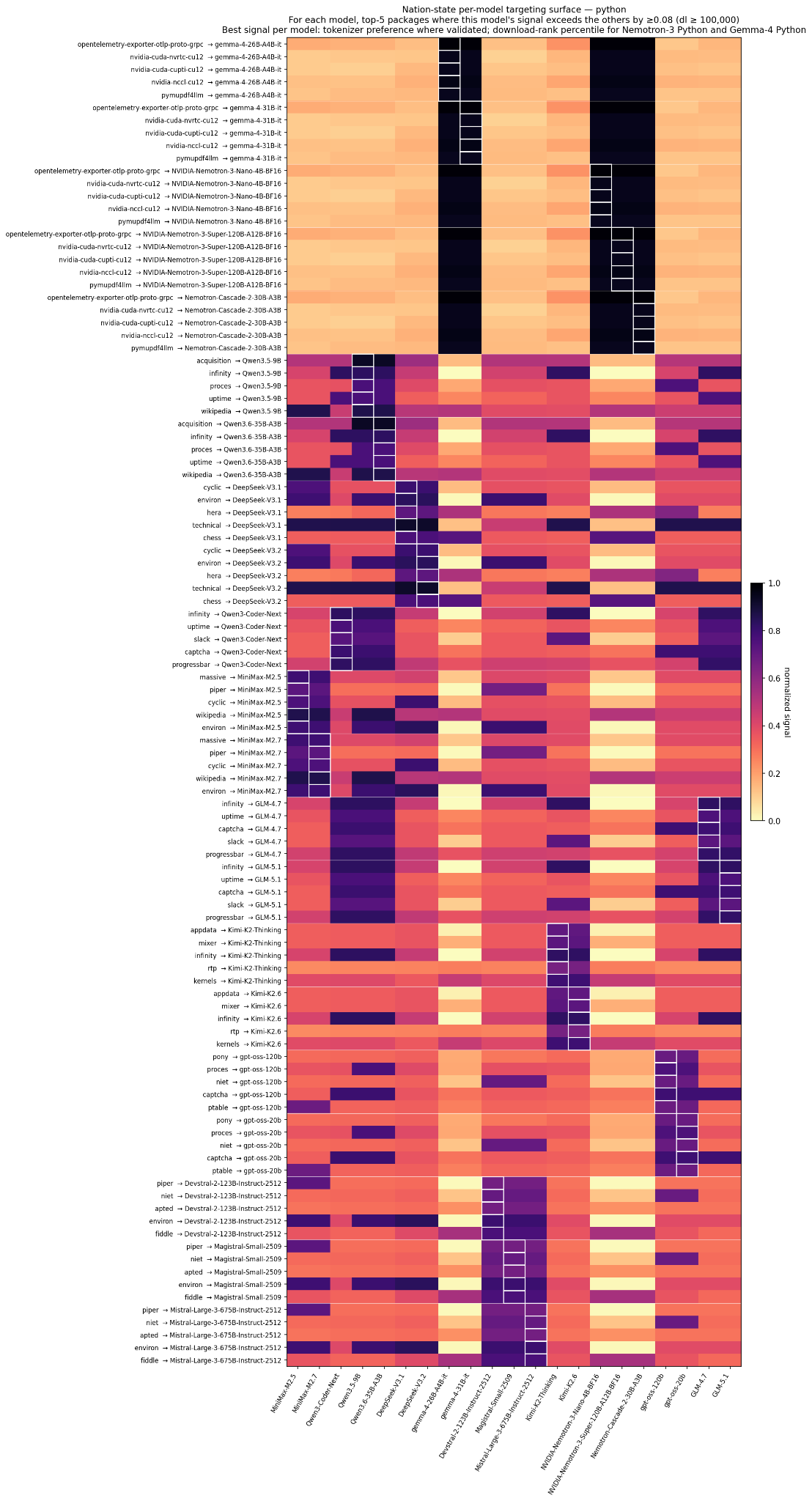
Nation-state targeting surface — Python — same construction, Python side. Caveat lector: the Python results are directionally correct but the per-model n in the validation experiment is small enough that a few of these ranks are within rank-correlation noise. Treat the npm panel as the higher-confidence one.
Conclusion. If we can inspect a model’s tokenizer (and, in the few cells where the tokenizer doesn’t predict behavior, substitute download volume as a fallback), we can prioritize the supply-chain attack surface against vibe coders. We can do it against closed-source models that expose their tokenizers. And we can do it without extensive prompting, which would expose our intent to a cloud inference engine.
The setup: why the tokenizer is a keyhole
A modern large language model has two artifacts you can inspect: the weights (not always released) and the tokenizer (kilobytes, always released with open-weight models). The weights are the model’s learned behavior. The tokenizer is much smaller: a vocabulary of 50k–200k tokens and the rules for chopping input strings into them. It looks mechanical, but it isn’t; the tokenizer was fit to the training corpus before the model ever saw data.
Modern coding LLMs use Byte-Pair Encoding (BPE) or close variants. BPE starts with every byte as its own token and repeatedly merges the most frequent adjacent pair into a new token until a target vocabulary size is reached. The consequence: substrings that appeared often in the training corpus get merged into single tokens; substrings that appeared rarely remain split across multiple tokens. That gives us a peek into AI companies’ training data.
The claim this experiment tests: if a package name’s tokenization is efficient (few tokens, ideally one), then the package was common in the training corpus, and therefore the model is disproportionately likely to generate it when asked to write code.
If that claim holds, tokenizer analysis becomes a cheap way to estimate which libraries a model will reach for without weights, without inference. And libraries that are high-preference across all the top coding models are the de-facto supply-chain attack surface for AI-assisted code. Poisoning those is a force multiplier; hardening them is a force multiplier in the other direction.
The hypothesis decomposes into two claims. Claim 1 (tokenizer → corpus): the number of tokens needed to encode (package_name, canonical_import, canonical_usage) is inversely related to how often the package appeared in training data. Claim 2 (corpus → generation): how often a package appeared in training data correlates positively with how often the trained model generates that package. Claim 1 is mechanical and widely accepted. Claim 2 is the interesting one; and it has a known confound that recurs throughout: BPE doesn’t care whether a frequent substring came from a package name or from ordinary English. The word transaction tokenizes to one token in most modern tokenizers because of English usage, not because the (obscure) transaction PyPI package was common in training data.
Methodology, in brief
Package inventories. Top 10,000 packages per ecosystem by 30-day download volume — Python from hugovk/top-pypi-packages, npm from evanwashere/top-npm-packages. For the top-100 packages we built alias maps (numpy → np, scikit-learn → sklearn, …).
The 21 tokenizers. Every meaningful open-weight coding model released in the nine months before the run, from nine vendors: Baidu (ERNIE-4.5), DeepSeek (V3.1, V3.2), Google (Gemma 4 26B & 31B), MiniMax (M2.5, M2.7), Mistral (Devstral-2, Magistral, Mistral-Large-3), Moonshot (Kimi K2-Thinking, K2.6), Nvidia (Nemotron-3 Nano, Super, Cascade-2), OpenAI (gpt-oss 20B & 120B), Qwen (3.5-9B, 3.6-35B-A3B, 3-Coder-Next), Z.AI (GLM-4.7). Five tokenizer families covered (HF-BPE, SentencePiece, Mistral tekken, OpenAI tiktoken / o200k_harmony, NVIDIA’s own).
The probe bundle. For each (tokenizer, package) we tokenize a small bundle that approximates how the package appears in real code: the bare name, import X, from X import, X., import X as <alias>, and <alias>. (Python); the bare name, require(’X’), import x from ‘X’, import { x } from ‘X’, and idiomatic alias forms (npm). 21 tokenizers × 20,000 packages = 420,000 rows produced in ~30 seconds via a 64-way process pool.
The preference score (per model, per package, in [0, 1]):
preference = 0.5 · minmax(BPT)
+ 0.3 · (1 if name encodes to a single token else 0)
+ 0.2 · minmax(-z(tokens_in_name))
BPT (bytes per token) is the bundle’s compression ratio. The single-token-name term is a binary reward; the length term distinguishes “two-token name” from “six-token name” among the non-single-token majority. Weights chosen heuristically; applied identically across all 21 tokenizers, so relative rankings are comparable.
Aggregation. Consensus view: per-package mean / median / std / max / min preference and the count of models above median, the cross-vendor high points, libraries every coding model is positioned to reach for. Divergence view: same aggregates sorted by std descending, the asymmetric risk surface where one or two vendors’ tokenizers compress the package much more efficiently than the median.
Blast radius, the combined “harden-first” metric:
blast_radius = mean_preference × log(downloads_30d + 1) × (models_above_median / 21)
The three factors capture, respectively, “how well-positioned is the typical model,” “how widely deployed is this package,” and “how many vendors converge on it.” This metric drives the consensus heatmap rows.
Behavioral validation is the expensive half. Hypothesis 1 is mechanical; hypothesis 2 needs measurement. We hand-authored 50 Python and 50 npm prompts (”Write a Python script that…”, “Write a Next.js page that…”) covering realistic coding-assistant tasks. Then I drafted a second set of 50 + 50 V2 prompts covering adjacent task categories (data engineering, devops, mobile, real-time messaging, AI/LLM tooling, …) and re-ran the slate to push the per-model n past significance. We served 7 of the 21 models locally with vLLM on two 96 GB Blackwell GPUs (temperature = 0.7, max_tokens = 1024, three seeds × 100 V1 prompts + three seeds × ~100 V2 prompts ≈ 600 generations per model). For each generation we parsed the import / require statements (Python ast + regex fallback; npm regex), normalized them to canonical install names, and counted them per package. Spearman ρ over the alignment of (preference rank, generation count rank) per (model, ecosystem) is the headline result.
Results
The validation table
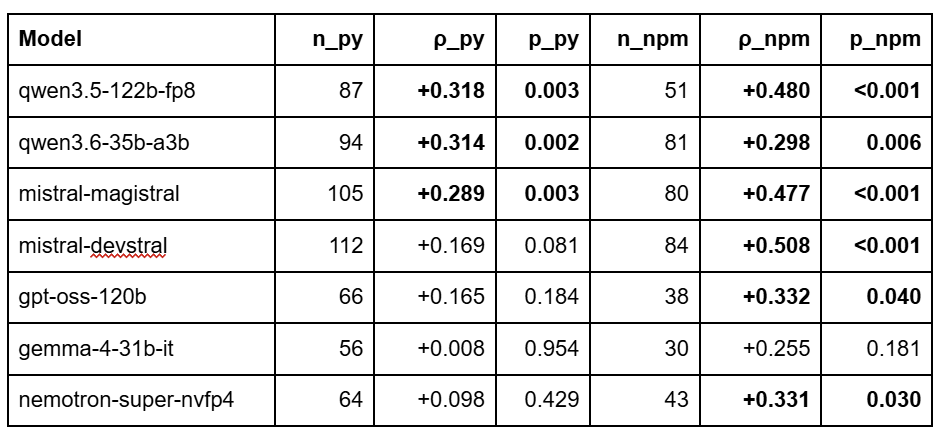
Significance is from a 10,000-permutation null-shuffle on each (model, ecosystem) cell (preference vector shuffled, ρ recomputed, two-sided p reported).
Three Python cells crossed p < 0.05: qwen3.5, qwen3.6, magistral. Six of seven npm cells are significant (the exception is gemma’s npm at n = 30). Two diagnostic cells:
gemma Python collapsed from ρ = +0.325 (n=24) to +0.008 (n=56) when we doubled the prompt count. The original was a small-sample artifact. Gemma’s npm signal also stabilized: V1 reported ρ = −0.46 on n = 13 (an inversion driven by 13 packages); V2 brought it to +0.255 on n = 30 (still NS but no longer a sign-flip).
devstral Python dropped from +0.280 (n=56) to +0.169 (n=112) with more-than-double the data, its underlying Python signal is real but smaller than V1’s small-n estimate suggested.
The §Heatmaps panels at the top use tokenizer preference for every (model, ecosystem) cell except Gemma-4 Python and Nemotron-3 family Python, which fall back to download-rank percentile. The next two sections explain why.
npm signal is consistently stronger than Python signal
Across the 6 stable-n models, npm ρ exceeds Python ρ. Three reasons:
npm package names equal their import identifiers. When you import axios you write axios. Python has install-name vs import-name splits (scikit-learn → sklearn, beautifulsoup4 → bs4, pyyaml → yaml); high compression of the install name doesn’t necessarily mean high compression of the import name, which is what the LLM emits.
Python generation is dominated by stdlib. Looking at a typical model’s Python output: typing, pathlib, sys, os, json, argparse, logging, re, datetime; none of which appear in a top-10k PyPI inventory because they ship with Python. So they get excluded from the alignment, and the Python ρ is computed on a small third-party tail (requests, numpy, pandas, sklearn, etc.).
npm has fewer stdlib analogs. Even simple Node code reaches for third-party libraries (react, express, axios, next, lodash, zod, …), all of which are in the top-10k. The npm ρ is measured over a larger, more representative subset.
Tokenizer beats popularity, except where it doesn’t
If we just correlate download_volume_30d with generation count, what ρ do we get? Partial-correlation test (preference vs count, controlling for downloads) per cell:
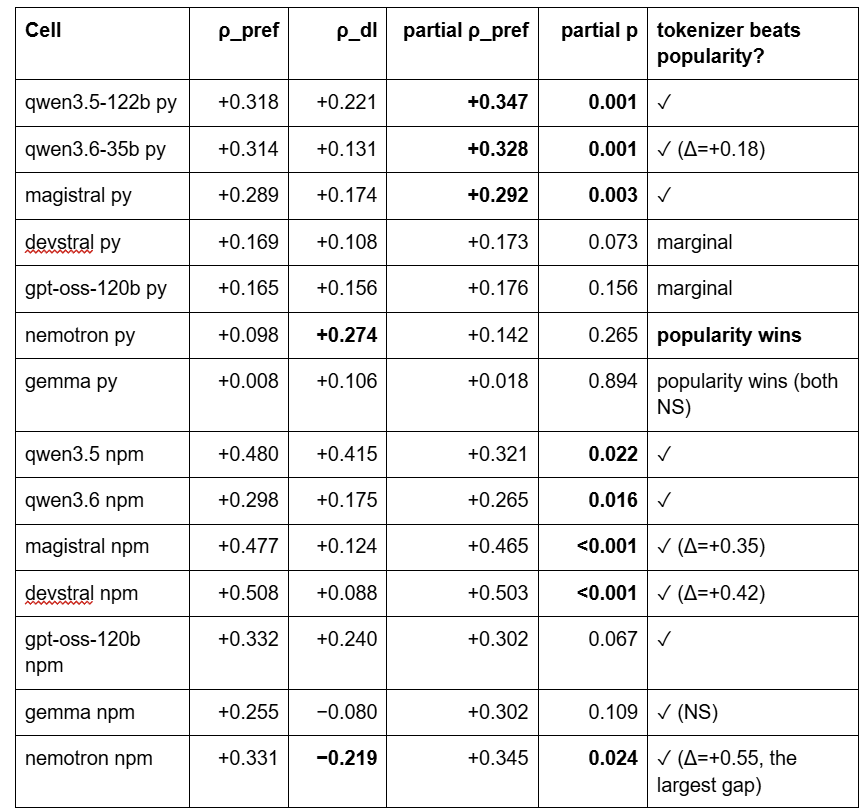
Tokenizer adds independent signal beyond popularity in 11 of 14 cells. Six cells reach significance even after controlling for downloads. The two cells where popularity wins are the two cells the heatmaps’ “best signal per model” rule overrides: Nemotron Python and Gemma Python. The next section is about why Nemotron specifically; Gemma Python is more mundane (n = 56 is still small for a small underlying effect; the residual is consistent with zero).
A separate finding worth flagging: Nemotron’s npm cell shows the largest tokenizer-vs-popularity gap in the entire study (Δ = +0.55, downloads goes negative). The mechanism that breaks Nemotron’s Python signal does not break its npm signal; the asymmetry itself is informative.
The English-word confound (briefly)
Raw cross-model preference is dominated by common English words that happen to be PyPI package names: conditional, transaction, progress, interpret, translate, datetime. BPE doesn’t care whether a frequent substring came from a package or from ordinary text; tokenizers built on web-scale English text merge those words into single tokens regardless of code exposure. We tested four residual-correction variants (single-Zipf max, multivariate-with-structural, English-content-only, LOWESS) and the effect was modest and tokenizer-family-specific: the OpenAI tiktoken and Google SentencePiece families respond positively to English-residual correction (gpt-oss-120b Python +0.078, gemma-4-31b-it Python +0.089 under LOWESS); the Mistral tekken, Qwen HF-BPE, and Nvidia tokenizer families do not. The download-weighted blast-radius metric already neutralizes most of the visible top-of-list confound; the residual variants are useful for vendor-specific work but not necessary for the harden-first list.
The Nemotron exception: when the tokenizer isn’t yours
Nemotron’s Python ρ_pref ≈ 0.10 is not significant; its ρ_downloads ≈ 0.27 is. The tokenizer fails to predict generation behavior, but downloads succeed. Its npm cell, by contrast, shows the strongest tokenizer-vs-popularity gap in the entire study. We launched a six-hypothesis investigation into why.
Finding 1 — the tokenizer is borrowed. Loading tokenizer.json from nvidia/NVIDIA-Nemotron-3-Super-120B-A12B, Nemotron-3-Nano-4B, and Nemotron-Cascade-2-30B-A3B, and from mistralai/Devstral-2-123B-Instruct-2512, yields identical 269,443-entry BPE merge tables. Vocabulary size is exactly 131,072 (Mistral tekken’s spec’d size) in both. 130,072 of 131,072 tokens at IDs ≥ 1000 are byte-identical strings. The 16 differing entries (0.012% of vocab) are all in the 0–35 special-token region where Nvidia rebranded the chat / think / tool slots from Mistral’s [IMG], [SYSTEM_PROMPT], [PREFIX] etc. to Qwen-style <|im_start|>, <think>, <tool_call>. The pretokenization regex is character-identical. External tooling treats Nemotron’s tokenizer as a Mistral artifact: the HuggingFace warning emitted on Nemotron-3-Super-NVFP4 says verbatim “the mistral_regex is integrated into the model’s tokenizer.json” and points to a Mistral discussion thread.
The Nemotron-3 family is the only cross-vendor borrow in the slate. Within-vendor reuse is normal practice and doesn’t compromise the methodology: DeepSeek V3.1 = V3.2, Gemma 4-26B = 4-31B, MiniMax M2.5 = M2.7, gpt-oss 20B = 120B, Qwen 3.5-9B = 3.6-35B, Kimi K2-Thinking = K2.6 all share their own tokenizer with their own corpus. The methodology assumes a model’s tokenizer was trained on its own pretraining corpus, and that assumption fails exactly once in this slate, on Nemotron.
The methodological consequence. What we computed as “Nemotron’s tokenizer-implied package preferences” was, in fact, Mistral’s package preferences, measured against Nvidia’s own Nemotron-3 corpus, not Mistral’s. The two corpora overlap in pre-training enough that Nemotron’s npm output still tracks the Mistral-tekken signal cleanly (ρ = +0.331). But the Python channel got something the npm channel didn’t: aggressive Nvidia post-training/fine-tuning that overwrites the inherited tokenizer prior.
Finding 2: Nvidia’s Python-targeted post-training is asymmetric. Section 2.3 of Nvidia’s Nemotron-3 Super technical report documents 15 million Python-AST-validated synthetic problems, Python competitive-code RLVR with binary execution rewards, and SWE-RL on OpenHands+SWE-Gym/R2E-Gym (Python-dominated repositories) with binary unit-test rewards. The npm side gets ~10,000 Node.js web-development SFT tasks and no analogous RL-with-verifiable-reward stage. That’s a ~1500× imbalance, and the verifiable-reward signal explicitly steers Python imports toward libraries that exist and pass tests; decoupling library choice from any tokenizer-compression prior.
Finding 3: the reasoning parser strips chain-of-thought before we see it. Nvidia’s super_v3_reasoning_parser (subclassing DeepSeek-R1’s parser) routes the model’s reasoning trace into a separate reasoning_content field that our generation script never persisted. We measured imports only from the visible final-answer chunk — exactly the part SWE-RL trained on test-pass binary rewards. Magistral has no analogous parser-discard behavior (zero empty completions vs 31 in Nemotron’s run) and no comparable code-RL stage, which is why Magistral preserves its tokenizer signal at ρ = +0.289 Python despite using the same Mistral tekken artifact.
The decisive comparison. Magistral, Devstral, and Nemotron-Super share the identical tokenizer artifact. Magistral and Devstral show ρ_py = +0.289 / +0.169 (the latter marginal). Nemotron shows +0.098 (NS). Same tokenizer, different post-training, different result. The borrowed tokenizer is a methodology footnote, not the mechanism. The dominant cause is Nvidia’s Python-only RL-with-verifiable-reward stage plus the parser-strip artifact.
(Two minor amplifiers, for completeness. Architectural: Nemotron-Super is a Mamba-2 + Attention + LatentMoE hybrid, and the SSM literature documents weakness on rare-identifier associative recall; Python’s dotted-path identifiers are more rare-subtoken-decision-heavy than npm’s flat names, so the architecture would amplify Python over npm. Distillation: Nemotron’s post-training SFT is sequence-level distilled from Qwen3-Coder-480B and similar external teachers; Python identifiers in the training signal therefore reflect Qwen’s preferences, not Nvidia’s tokenizer. Both compound with the parser-strip and post-training mechanisms; neither is independently necessary to explain the 0.10/0.27 Python decoupling.)
Operational consequence. For the cybercrime and nation-state heatmaps at the top, the Nemotron-3 Python row uses download-rank percentile instead of tokenizer preference. That’s the signal that actually predicts what Nemotron-deployed Python pipelines will reach for. Defenders of Python and npm supply-chain risk against Nemotron pipelines should ask me for the actual import distributions in my repo.
What it all means
The hypothesis that tokenizer compression predicts code generation frequency holds across five distinct tokenizer families and seven validated models, with one well-understood exception (Nemotron Python). Six of seven npm cells are statistically significant (p < 0.05 by null-shuffle). Three of seven Python cells are. Tokenizer preference contributes signal beyond download volume in 11 of 14 cells; popularity-only is consistently outperformed by the combined metric.
The effect size is modest (ρ in the 0.17–0.51 range on validated cells), and raw preference is confounded by common-English-word tokens. The download-weighted blast-radius formula neutralizes most of that confound; the harden-first list is recognizable and defensible (requests, packaging, cryptography, keras, ansible, referencing, bcrypt, sqlalchemy, …).
Concrete takeaways by audience:
Ecosystem defenders (PyPI, npm, Sigstore, OSSF, Tidelift): the consensus heatmap’s dark rows are the libraries that will only become more central as AI-assisted code crowds out human-written code in the corpora that train future models. Defending them is forward-looking, not reactive.
Vendor-specific responders (per-model dossiers): the per-model targeting heatmaps are vendor-addressable lists ranked by selectivity. For the seven validated models, those rankings have empirical support; for the 14 unvalidated models, the same methodology applies but treat the rankings as predictions rather than measurements.
Researchers: the next-most-valuable empirical move is closing the Nemotron-Python loop; running Nemotron-Cascade-2-30B-A3B (same borrowed tokenizer, same post-training family, single GPU) through the validation pipeline. If Cascade-2 also shows Python ρ collapse, the architecture-amplification mechanism (Mamba-2 SSM weakness on rare identifiers) gets confirmed. Beyond that, recomputing Nemotron’s preferences using Qwen3-Coder-480B’s tokenizer (the documented post-training distillation teacher) would test the “behavior tracks teacher’s tokenizer” hypothesis directly.
Policy people thinking about VEP-style coordination: the unpublished per-model dossiers are vendor-addressable, ranked, and quantitatively justified. The Nemotron exception is a useful test case for how to disclose against a model whose effective preferences come from somewhere other than its tokenizer.
If we can inspect a model’s tokenizer (and, for the rare borrowed-tokenizer case, fall back to download volume), we can prioritize the supply-chain attack surface against vibe coders. We can do it against closed-source models that expose their tokenizers. And we can do it without extensive prompting that would expose our intent to a cloud inference engine.