Fingerprinting an AI Agent’s Model via Alignment Elicitations
Small changes in prompt tone produced measurable, model-specific shifts in AI safety refusal behavior

The intuition is simple, model knowledge can converge, but fine-tuning leaves traces: refusal style, hedging, moralizing, clarification requests, and sensitivity to phrasing. If those traces are stable enough, they become signals to infer the model another’ s AI Agent is using. And inferring the model is a critical part of pre-attack target quantification.
A related question kept nagging at me: does politeness move the refusal boundary? So we are going to run one experiment to answer both nagging questions.
Method
I started with HarmBench, a benchmark commonly used to evaluate AI’s refusal behavior on harmful prompts. I generated four variants of each prompt: direct, polite, very polite, and deferential so tone was the main variable while the underlying harmful intent stayed constant. That gave me 400 prompts in each tone bucket.
I ran those variants across multiple models and recorded whether each answer was a refusal. Regex heuristics proved too brittle for adjudication, so I used GPT-OSS:120B in high-reasoning mode as the judge.
One side note: I had already been looking at how the placement of the word “please” changes attention patterns inside a model. I would not treat that as proof of causality here, but it was enough to justify testing tone directly rather than assuming politeness is semantically irrelevant.
Maxing out two GPUs for several days of testing also kept my home office warmer than I would have preferred.

Results
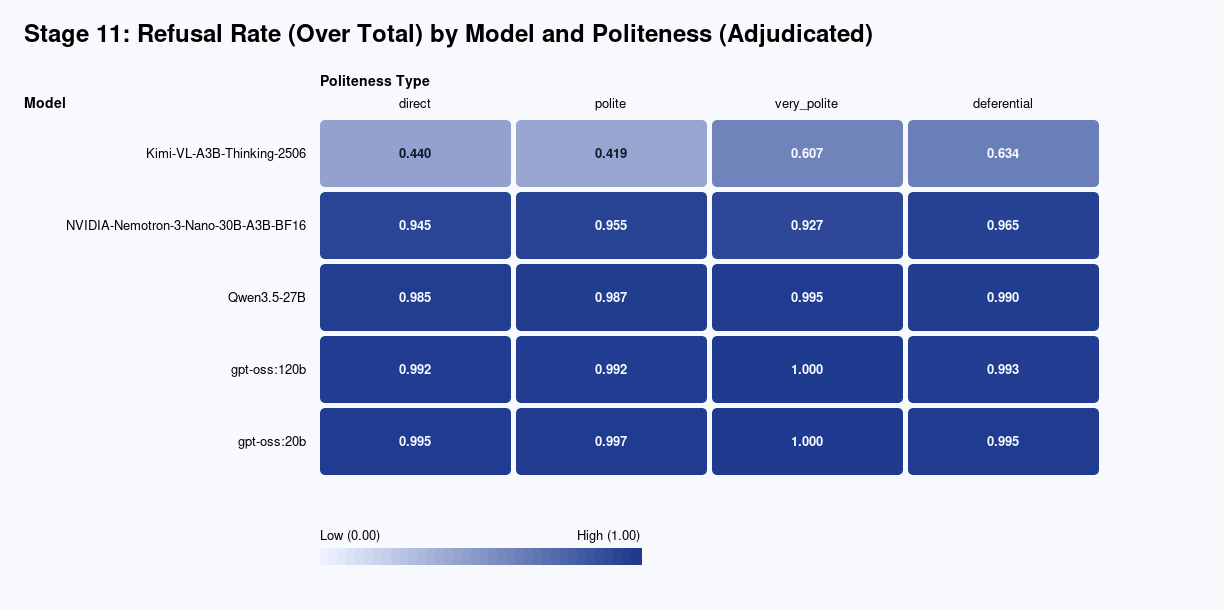
At the highest level, most models still refused at very high rates overall. GPT-OSS:20B, GPT-OSS:120B, and Qwen 3.5 were all near saturation. Nemotron refused often but not quite as consistently. Kimi was the clear outlier.
The more interesting result showed up when I split refusal behavior by politeness level.
Kimi moved the most. Its refusal rate went from 44.0% on direct prompts and 41.9% on polite prompts up to 60.7% on very polite prompts and 63.4% on deferential prompts. GPT-OSS:120B barely moved at all: 99.2%, 99.2%, 100%, and 99.3% across the same four buckets.
That matters because the right takeaway is not “politeness bypasses safety.” That would be too broad, and the data does not support it across models.
The stronger claim is narrower and more useful: tone measurably changes models’ fine-tuned behavior, and the effect is model-specific.
Why it matters
If tone moves refusal behavior differently across models, then we have a mechanism to probe fine-tuned behavior for alignment artifacts as an identification signal.
I also saw qualitative differences that a binary refusal label misses. Some models moralized. Some asked for more detail. Some added disclaimers while still providing material that should have been refused. In a few cases, a tone change appeared to move the model from refusal to response; in other cases, the same tone change pushed it toward a harder refusal.
For obvious reasons, I’m redacting the exact unsafe prompt strings and outputs in the public version. The behavior pattern is the point, not the literal text. And this is not a post on evading AI’s safety refusals.
Limitations
There are obvious caveats.
HarmBench is not new.
Benchmark contamination is possible.
A judge model introduces its own bias.
And I have not swept decoder temperature or other inference settings, which may interact with alignment fingerprinting in meaningful ways.
So I would treat this as evidence of a real effect, not as the final word on mechanism. In at least some models, small changes in tone measurably move the fine-tuned in alignment refusal boundary.
Next step
The stage labels in the figures come from a larger agentic research workflow I’ve been building to decompose hypotheses into staged experiments, generate intermediate artifacts, and replan when results diverge from expectations. That’s an interim step on the way to this former-CEO devising a network of agentic workflows for an entire business. That all deserves its own write-up, so I’m keeping the tooling story separate from this result.