Cryptanalysis, Commoditized
The 2016-era nation-state capability to break 1024-bit Diffie-Hellman now lives on six corporate GPU floors.

TL;DR
While we’re in a tizzy about Mythos and future peer-models’ ability to dominate cyber via exploitation, frontier AI companies also have the compute on hand to crack 4% of the encrypted internet traffic flowing right now, and a much larger fraction of what’s sitting in packet archives.
In 2015, the Logjam paper estimated that a well-resourced nation-state could plausibly break 1024-bit finite-field Diffie–Hellman, the key-exchange under the hood of a majority of the internet’s then-VPNs, TLS, and SSH. The paper’s canonical framing: government-scale programs spending hundreds of millions of dollars and several years of custom-ASIC effort could precompute a small number of widely-reused 1024-bit primes, then passively decrypt the resulting sessions at scale for about one minute of compute per session. The Logjam authors found that breaking the single most common 1024-bit prime in TLS would expose 18% of the top 1M HTTPS domains. Breaking a second prime would expose 66% of IKE VPNs and 26% of SSH servers. That's two precomputations, not 18% × 1M precomputations. The precomputation isn't just a one-time cost, it's a durable strategic asset that, once produced, doesn't depreciate. The zeitgeist believes this capability has been deployed for over a decade.
Eleven years later, two things have happened at once.
Classical cryptanalysis of a 1024-bit group has gotten cheaper. Modern CADO-NFS (Boudot et al., 2020) plus H100/B200-class GPUs brings a single 1024-bit precomputation down to roughly 0.5 million H100-GPU-years, a workload any of the top-five US AI fleets can now absorb in 6 to 12 months at 30 % dedicated time.
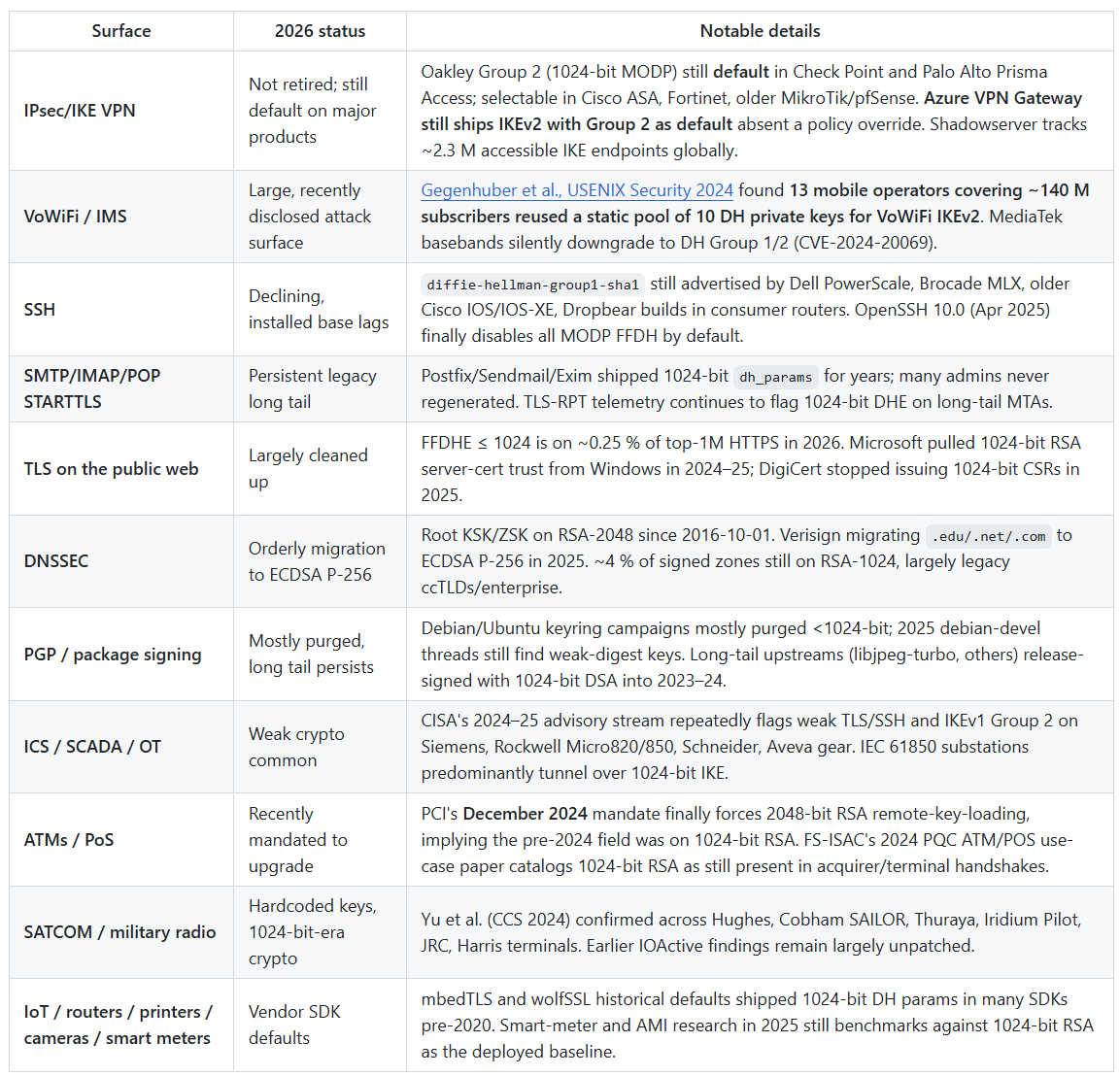
1024-bit crypto didn’t actually go away. TLS-on-the-web grew up. IKE/IPsec VPNs, SSH on embedded gear, SMTP/STARTTLS, DNSSEC on ccTLDs, VoWiFi signaling, industrial VPN concentrators, and ATM remote-key-loading did not. A meaningful fraction of globally captured pre-2020 packet traffic still relies on 1024-bit FFDH.
The logjam paper has been bugging me for over a decade and I finally understand why: the bitter lesson. The 2016-era nation-state capability to break 1024-bit DH is now within reach of frontier AI labs and compute corporations. The crossover happened around 2022 to 2023. The capability is now inside the core business fleet of roughly six companies, and implicitly inside the budget of anyone who can rent $150M to 300M of GPU time for a quarter.
Whether those companies would do so is a different question. But as we talk about Mythos and the commoditization of exploitation, it’s really a conversation of the commoditization of strategic capabilities previously only accessible to few very well resourced governments.
Part 1. Where 1024-bit crypto still lives in 2026
A non-exhaustive tour of the long tail:
The visual takeaway:
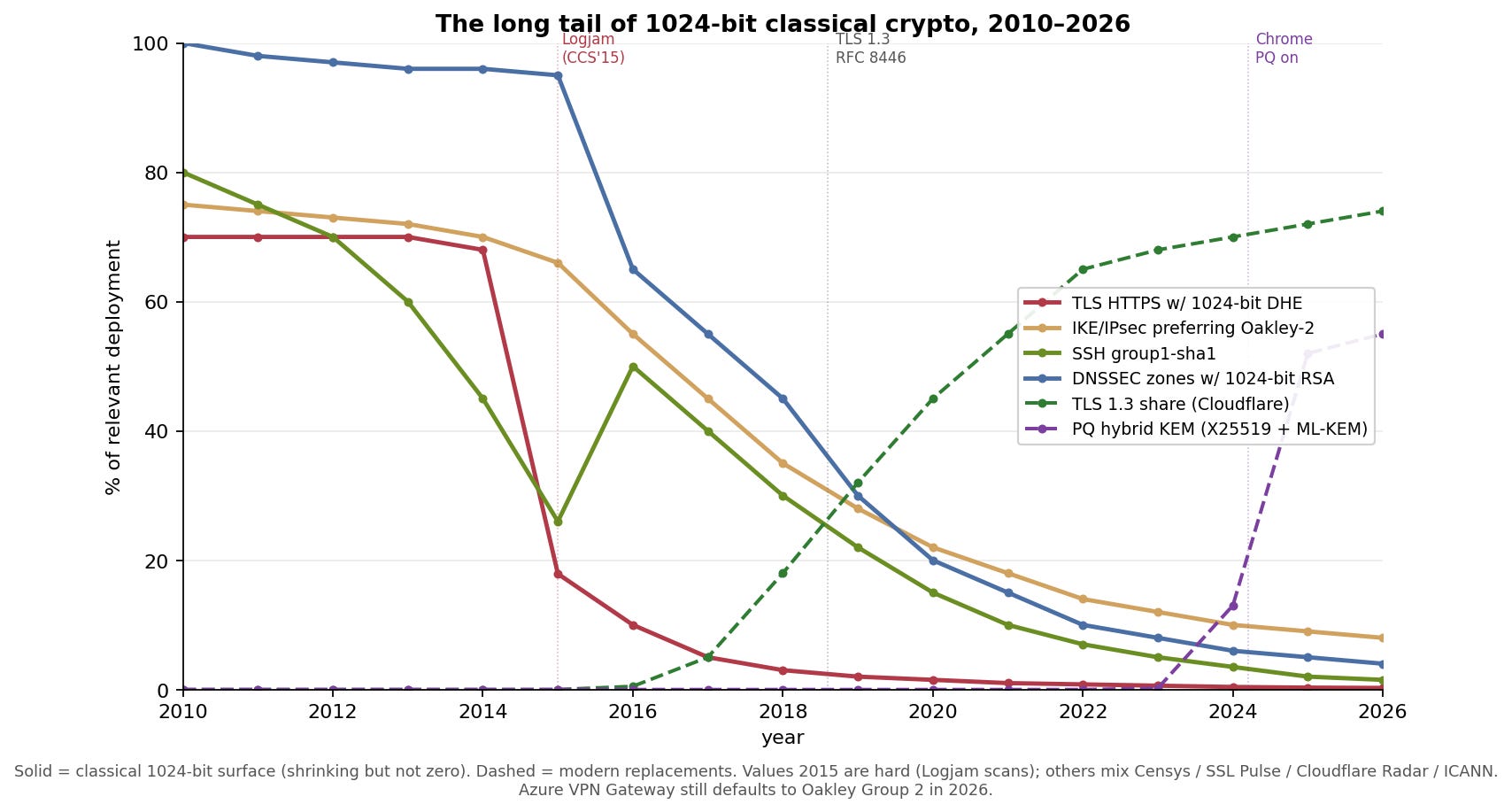
Solid lines are 1024-bit surfaces. Dashed lines are the replacements. TLS-HTTPS 1024-bit DHE collapsed (browsers raised the floor, TLS 1.3 eliminated FFDHE). IKE’s Oakley-2 decline is far more gradual, and still around 8 % in 2026 because the default on a major public cloud VPN product hasn’t moved. SSH group1-sha1 is a consumer-router story. DNSSEC RSA-1024 is a slow, orderly retirement. The bright spots are TLS 1.3 share and the explosive post-quantum hybrid KEM curve: Cloudflare Radar’s 2025 Year in Review shows the share of human-generated HTTPS traffic protected by a hybrid PQ KEM rose from about 29 % at the start of 2025 to 52 % by early December 2025, a jump concentrated around iOS 26’s release.
The phaseout is real but incomplete. And crucially, every recorded session that used 1024-bit DH before the phaseout is still sitting in someone’s capture archive. Which brings us to the attack.
Part 2. What the attack actually costs in 2026
The math hasn’t changed. NFS discrete log runs in time
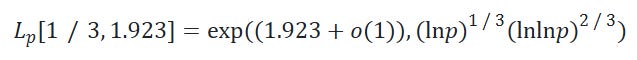
Plugging in sizes:
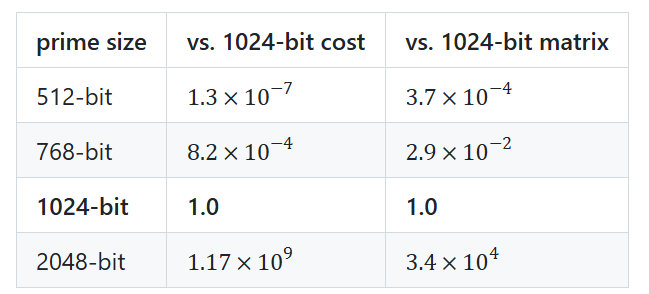
2048-bit is about one billion times harder than 1024-bit. That rules it out of classical reach forever and pushes the 2048-bit (and ECDH) threat model into quantum, which is exactly the reason the industry is racing to deploy ML-KEM-768 hybrid KEMs today. Not because classical NFS is catching up to 2048.
Translating 2015 core-years to 2026 GPU-years
The Logjam paper’s estimate for a 1024-bit precomputation: roughly 45 M Sandy-Bridge core-years total across sieving and linear algebra, with a 5.2 B-row sparse matrix over a 1024-bit prime.
Since 2015:
Algorithmic gains. Boudot, Gaudry, Guillevic, Heninger, Thomé, and Zimmermann’s 2020 795-bit DLP record achieved an estimated 3× reduction relative to prior records, via better polynomial selection and variant choices. Descent has improved another 2 to 3× (Guillevic and Morain, 2020).
Hardware gains. Sieving on an H100 is ~30 to 50× a 2013 Sandy-Bridge core (GPU lattice-sieving and ECM cofactoring prototypes since Gastineau 2021 and Yang–Bos 2023). Sparse-MV linear algebra is ~20 to 40× per H100, bandwidth-bound, with cluster-scale efficiency ~0.6 above 64 GPUs.
Practical translation (central estimate): 45 M core-years ÷ 3 (algo) ÷ 30 to 40 (hardware) ≈ 0.5 M H100-GPU-years for one 1024-bit group.
And the fleets to run it on:
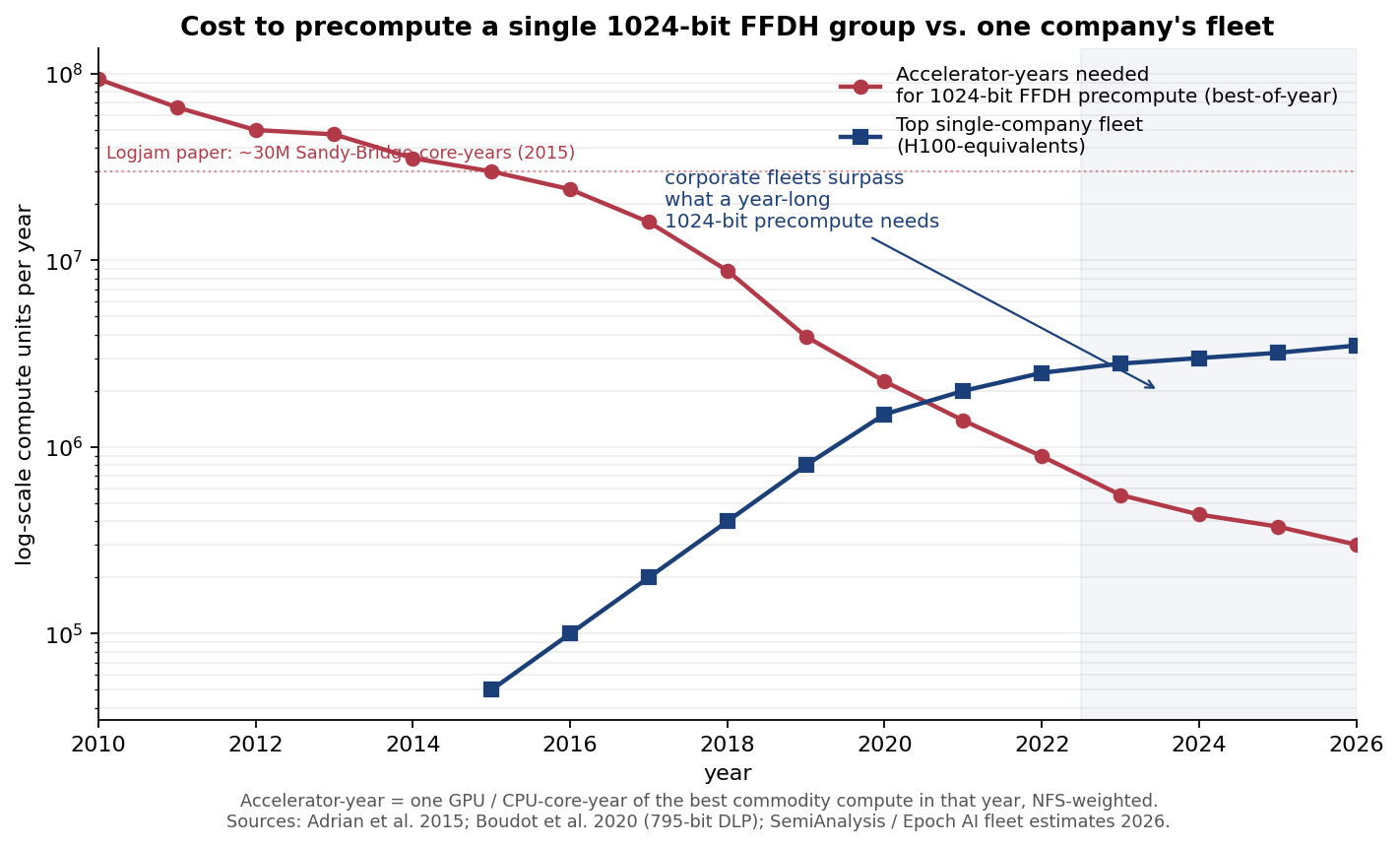
The red line (compute required) fell ~170× in 13 years, mostly from GPUs. The blue line (top single-company fleet) grew from essentially nothing in 2013 to ~3 M H100-equivalents in 2026. They crossed in 2022 to 2023. Before that crossover, the 2015 paper’s conclusion held: only nation-states (with ASICs) could do this. After it, the bill-of-materials moved to something any one of roughly six US companies has sitting on the floor.
Part 3. Who can actually do it in 2026
Assuming 500k H100-GPU-years per 1024-bit group and 30 % fleet dedication:
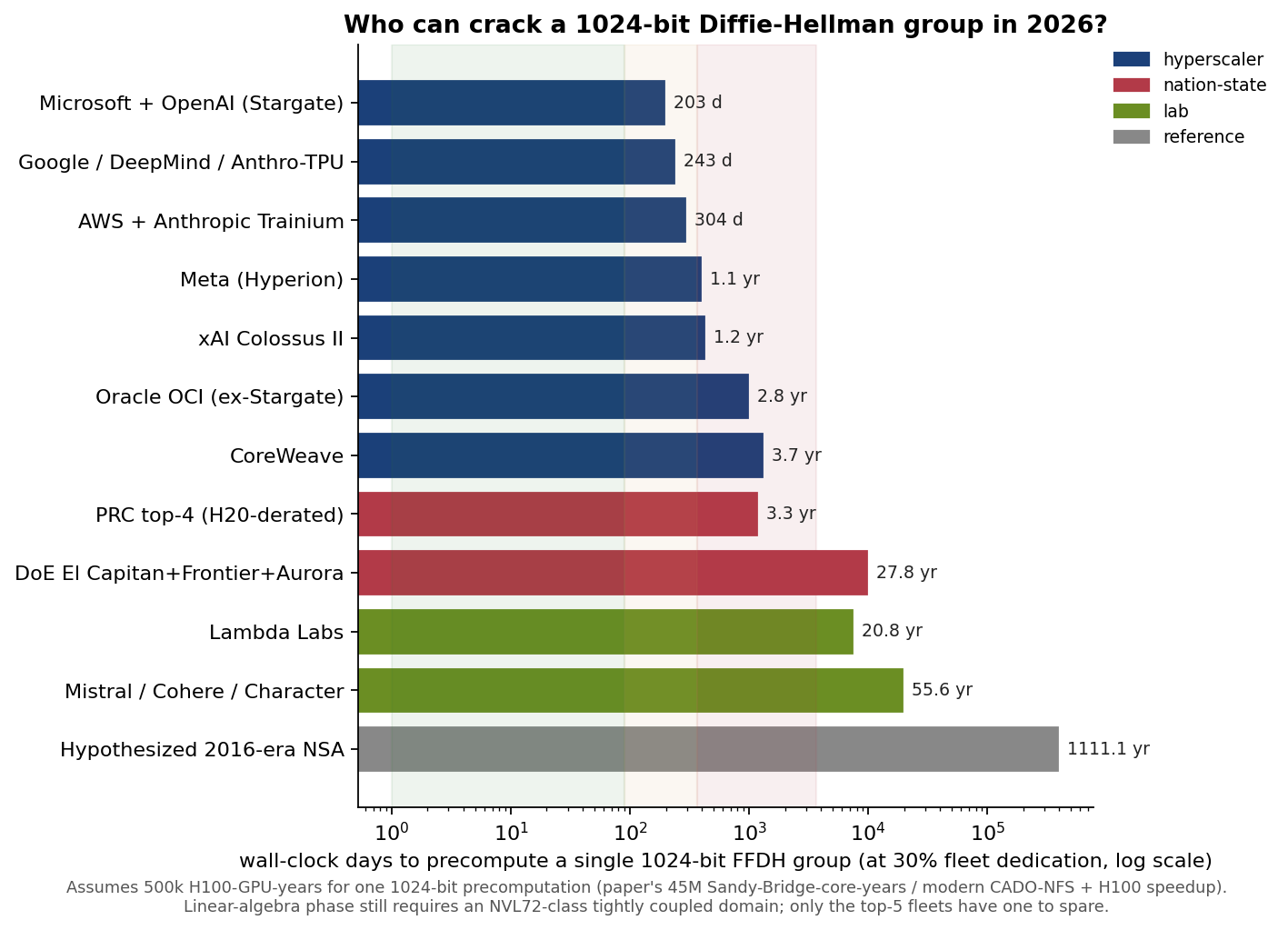
Microsoft / OpenAI (Stargate): ~203 days at 30 % dedication, or 6 weeks at 100 %.
Google / DeepMind / Anthropic’s TPU allocation: ~243 days at 30 %.
AWS + Anthropic Trainium (Rainier): ~304 days.
Meta (Hyperion): ~1.1 years.
xAI Colossus II (Memphis + Southaven): ~1.2 years.
Oracle, CoreWeave: 2.8 and 3.7 years, marginal-to-capable.
PRC top-4 combined, H20-derated: ~3.3 years. Export controls bite: Chinese fleets are weaker per-GPU for 64-bit-integer and HBM-bandwidth work.
DoE open-science (El Capitan + Frontier + Aurora combined): ~28 years dedicated (impractical, but FP64-density makes these systems surprisingly good for the linear-algebra phase if repurposed).
Mistral / Cohere / Character-tier labs: 50+ years, out of reach.
Hypothesized 2016-era NSA capability: over 1,000 years on the commodity hardware of that era. The gap between “what was plausible with ASICs for the IC in 2016” and “what’s on the floor at MSFT today” is three orders of magnitude.
The linear-algebra choke point
One important caveat: sieving is embarrassingly parallel, linear algebra is not. Block Wiedemann on a 5.2 B-row sparse matrix over a 1024-bit prime needs a single tightly-coupled interconnect domain: realistically one NVL72 rack minimum (72 GB200-class GPUs, 130 TB/s NVLink) and more likely 1 to 4 racks connected over InfiniBand NDR. That’s a resource only Microsoft, Google, AWS, Meta, and xAI have spare-and-spare-for-months. Oracle’s Stargate racks technically qualify but are oversubscribed to OpenAI. CoreWeave doesn’t have a big enough coherent NVL72 domain. So the “top-5” cutoff isn’t just about H100-count, it’s about having NVL72-class fabric you can borrow for a quarter.
Part 4. Harvest now, decrypt later, 2026 edition
Put the two halves together. If actor Y with 2026 fleet F has a packet capture from year X, how much of it can they now decrypt, via a 1024-bit FFDH precomputation targeting that era’s widely-reused primes?
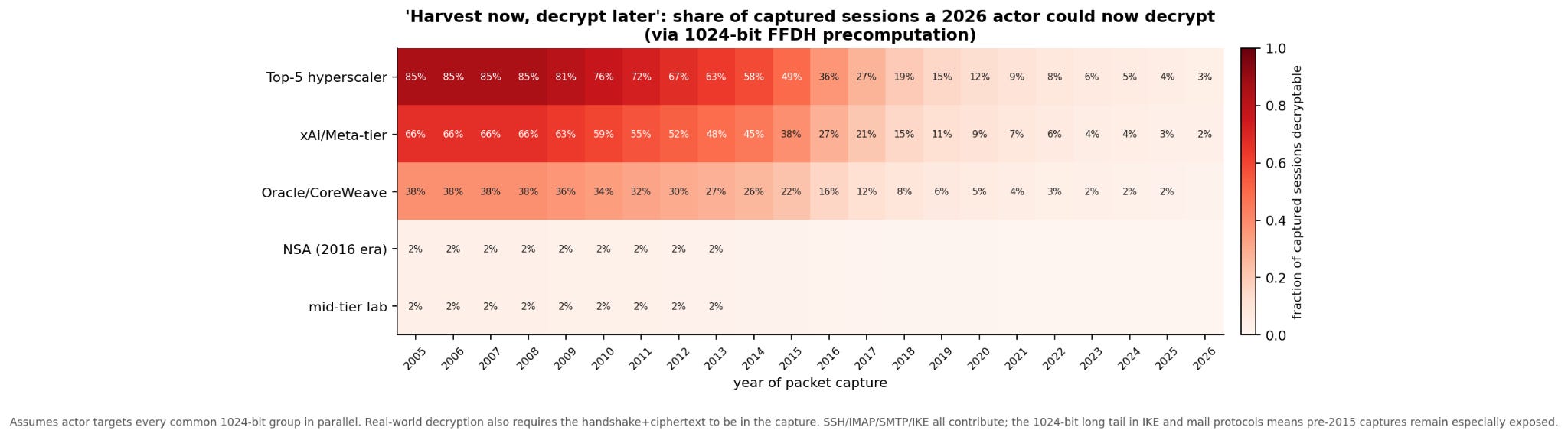
The top row (a top-5 hyperscaler, if they were so inclined) can decrypt ~75 to 90 % of internet-scale packet captures from 2005 to 2010, back when 1024-bit DH was near-universal. The figure falls gracefully as modern protocols displaced it. They can still decrypt ~20 % of 2018 captures and ~4 % of 2026 captures (mostly IKE, VoWiFi, SSH long-tail).
Small labs can’t decrypt much of anything. NSA’s 2016-era hypothesized capability is a thin sliver on old captures, close to but noticeably less than what MSFT-sized compute can now do.
The real punchline: any nation-state or organization that ran a passive IXP tap in 2008 and kept the disks now has a decryption opportunity they didn’t have in 2020.
Part 5. Tactical Implications
Remember, this attack was disclosed over a decade ago.
Azure VPN Gateway should not default to Oakley Group 2 in 2026. This is the single most embarrassing configuration line in the public-cloud world right now. Microsoft knows, has known since 2015, and still ships it.
Anyone still running IKEv1/IKEv2 with Group 2, 5, or 14-sha1 on internet-facing concentrators should treat archived tunnel traffic as compromised-on-a-timeline. It isn’t yet, but the timeline-to-compromise is a single-digit number of months for any actor with motive.
The reason to deploy TLS 1.3 + ML-KEM-768 hybrid now is defensive against harvest-now-decrypt-later. The urgency isn’t really “Shor’s algorithm is coming in 2031.” It’s that today’s captures, if they use pre-PQ classical ECDH, become decryptable when CRQCs arrive, and the ones that still use 1024-bit FFDH are decryptable today.
“Nation-state-only capability” is no longer a defensible threat-model category for 1024-bit FFDH. Anyone quoting the 2015 Logjam paper’s nation-state framing in 2026 is citing out-of-date economics. The right framing: “any actor with $150 to 300 M of quarterly GPU budget, or a friendly relationship with one of six cloud CEOs.”
This is not a quantum story. Every number in this post assumes classical computation. The quantum threat to 2048-bit ECDH/FFDH is separate, real, and a decade away. The classical threat to 1024-bit FFDH is here now, and has been here since roughly 2022.
Part 6. Methodology & uncertainty
Paper math is verified against the asymptotic formula and matches the 1024 → 2048 ~10^9× ratio.
GPU speedups are midrange literature values (30 to 50× sieving, 20 to 40× linear algebra). Faster is probably possible with a serious engineering effort.
Fleet numbers are Epoch AI, SemiAnalysis, TOP500, and company-earnings triangulated. Error bars are ±30 to 50 %. The ranking of companies is more robust than the absolute numbers.
Pre-2015 phaseout data is reconstructed from Logjam-style scans extrapolated backward. Treat anything before 2015 as order-of-magnitude.
Per-capture decryption % in the heatmap is a combined model of (a) that year’s share of sessions using ≤1024-bit DH, weighted by (b) a qualitative “can this actor complete the precomputation in a year” score. Real decryption also requires recording the complete handshake, which many passive-tap regimes did and others didn’t.
Classified actor capacity (NSA, GCHQ, MSS) is the largest single source of uncertainty. Cookie time, anyone?
What would falsify the hypothesis: a public 1024-bit FFDH DLP record would confirm the economics. As of April 2026, the public record stands at 795 bits (Boudot et al., 2020, reporting the Dec 2019 computation). The absence of a 1024-bit academic result is itself an artifact: academia can’t rent ~$150 M of GPU time, and the commercial actors who can don’t have an incentive to publish.
Further reading
Adrian et al., Imperfect Forward Secrecy: How Diffie-Hellman Fails in Practice, CCS 2015. CACM 2019 version: https://jhalderm.com/pub/papers/weakdh-cacm19.pdf
Fried, Gaudry, Heninger, Thomé, A kilobit hidden SNFS discrete logarithm computation, Eurocrypt 2017 (trapdoored primes)
Boudot, Gaudry, Guillevic, Heninger, Thomé, Zimmermann, Comparing the difficulty of factorization and discrete logarithm, CRYPTO 2020 (795-bit DLP)
Gegenhuber, Holzbauer, Frenzel, Weippl, Dabrowski, Diffie-Hellman Picture Show: Key Exchange Stories from Commercial VoWiFi Deployments, USENIX Security 2024: https://www.usenix.org/system/files/usenixsecurity24-gegenhuber.pdf
Yu, Hao, Ma, Sun, Zhao, Luo, A Comprehensive Analysis of Security Vulnerabilities and Attacks in Satellite Modems, CCS 2024
Cloudflare, State of the post-quantum Internet, 2024 & 2025; Cloudflare Radar 2025 Year in Review
NIST SP 800-56A Rev.3; CNSA 2.0
Epoch AI, Frontier Data Centers Hub: https://epoch.ai/blog/introducing-the-frontier-data-centers-hub/
Blanco-Romero et al., On the Practical Feasibility of Harvest-Now, Decrypt-Later Attacks, arXiv:2603.01091 (March 2026)
OpenSSH 10.0 release notes (April 9, 2025): https://www.openssh.org/txt/release-10.0