After The Mythos Moment
If history rhymes, vulnerability discovery shocks normalize and exploit automation compounds.

Anthropic’s April 7 announcement of Claude Mythos Preview has produced the expected doom cycle: AI is going to find all the bugs, defenders will drown in CVEs, and the security industry is staring into a “vulnpocalypse.”
The core fear is not irrational. Mythos-class models appear to be materially better at vulnerability discovery, exploit development, and exploit chaining than prior public systems. But the first question people are trying to answer from public data, “Are CVE counts already spiking because of Mythos?”, is the wrong question, or at least the wrong instrument.
Published CVEs are not observations of discovery. They are observations of publication. They lag discovery by vendor triage, coordinated disclosure, CVE numbering behavior, NVD processing, patch timing, and ordinary reporting incentives. Looking for a Mythos signal in public CVE counts five or six weeks after the announcement is like trying to measure a new telescope by watching when astronomy journals print papers.
If I cut to the chase: we have seen a vulnerability-discovery shock before. In 2015–2017, a cohort of automated vulnerability-discovery tools and competitions changed what got found. The shock was real. It did not produce permanent acceleration. It produced a one-time harvest, followed by saturation, adaptation, and a broader reporting expansion that made raw CVE counts increasingly hard to interpret.
That is the right historical analogy for Mythos. Not “nothing will happen.” Not “everything changes overnight.” The more likely pattern is a delayed and noisy reporting signal, a temporary discovery harvest in model-suitable bug classes, and a much more important shift in exploit generation.
The 2017 vulnerability-discovery shock
The change-point analysis below shows the breakpoints in vulnerability reporting rate. The important break is January 2017. Something changed in the 2015–2016 window, and the effect appeared in public reporting later, consistent with responsible-disclosure lag and adoption lag.
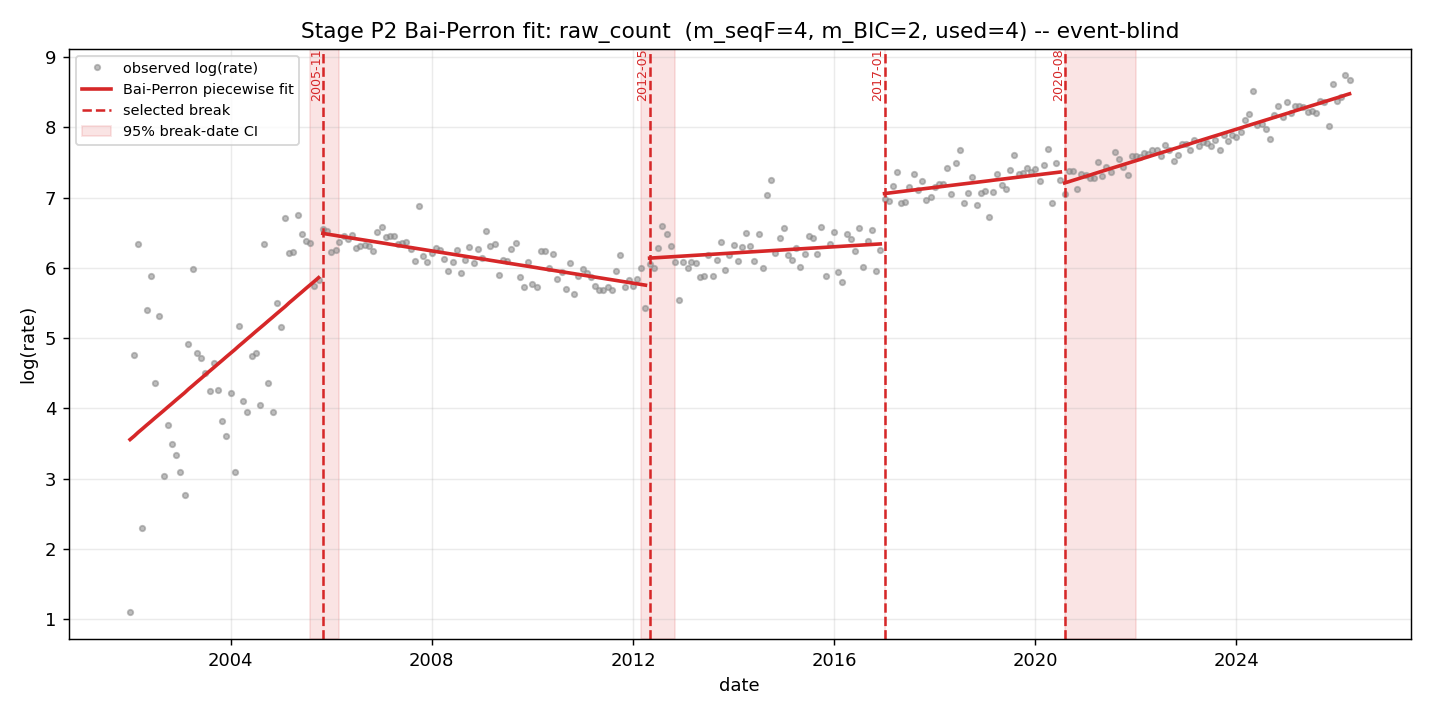
The obvious temptation is to look for a single “killer event.” The data does not support that. The cleaner interpretation is a cohort effect: DARPA’s Cyber Grand Challenge Qualification and Final Events, libFuzzer, syzkaller, OSS-Fuzz, and the broader move toward automated continuous fuzzing. I’ll note here that these breaks were detected blind to a frozen event catalog so I didn’t risk fitting events that I was a part of to a curve.
That cohort did not just increase the number of vulnerabilities reported. More importantly, it changed the mix of vulnerabilities being found.
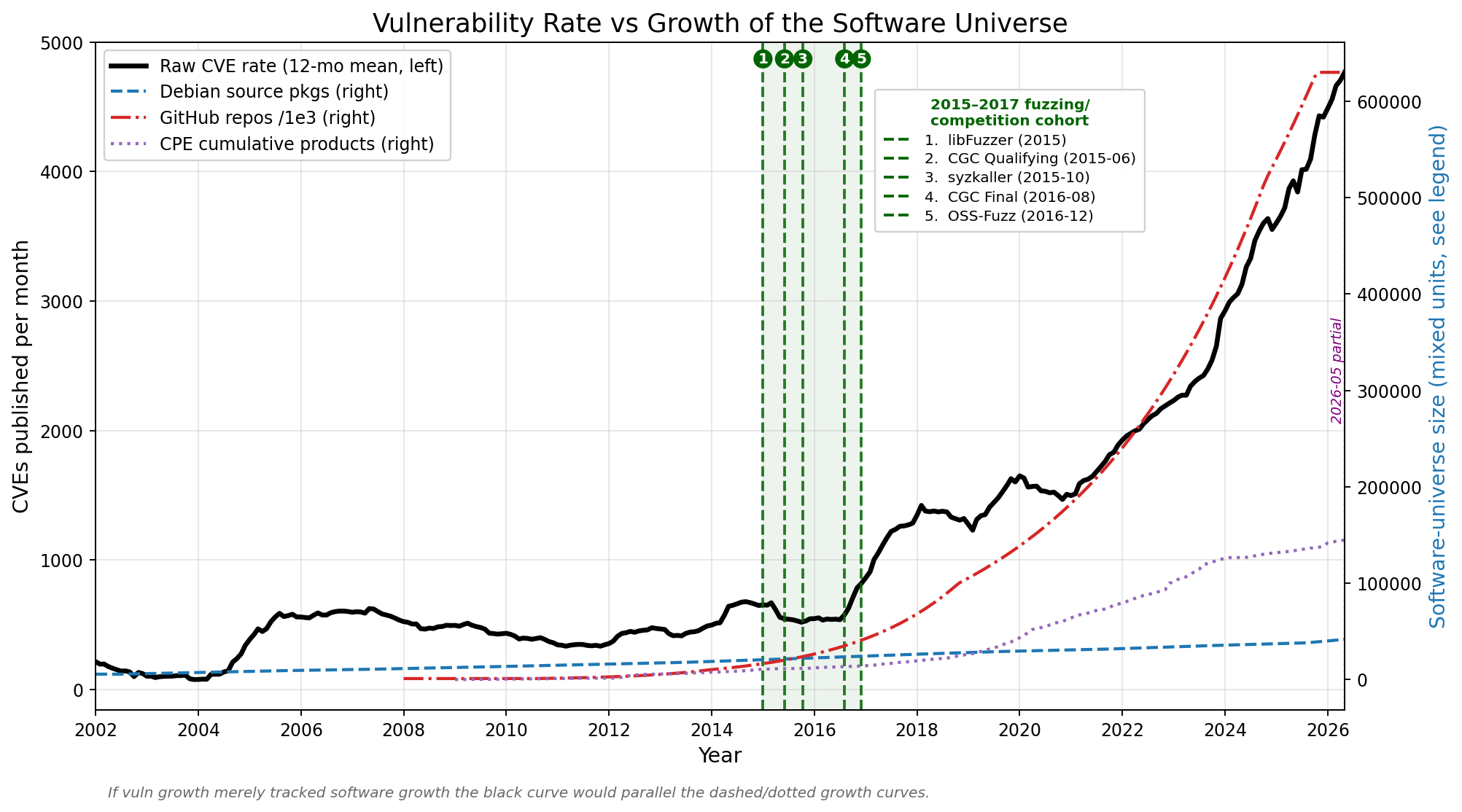
The CVE and NVD curves tell the reporting story. They show that public vulnerability volume rises dramatically after 2017. But raw publication volume alone cannot tell us whether discovery became permanently more efficient. For that, the better signal is composition: what kinds of bugs were being found?
The discovery fingerprint: memory safety
The clearest discovery-side fingerprint from the 2015–2017 cohort is memory safety. These are the bug classes automated fuzzing and symbolic execution is especially good at finding.
Before the cohort, memory-safety vulnerabilities were roughly 14–20% of reported vulnerabilities. During the cohort, the share rose sharply: about 31% in 2016 and 32% in 2017. That is a real level shift.
Then it stopped rising.
The share plateaued and then steadily declined: about 29% in 2018, 24% in 2020, 20% in 2023, and 17% in 2025. Meanwhile, web-injection and adjacent web-class vulnerabilities moved the other direction, rising from roughly 16% in 2016 to 42% in 2025, with the 2023 reporting-format break making that shift even more visible.
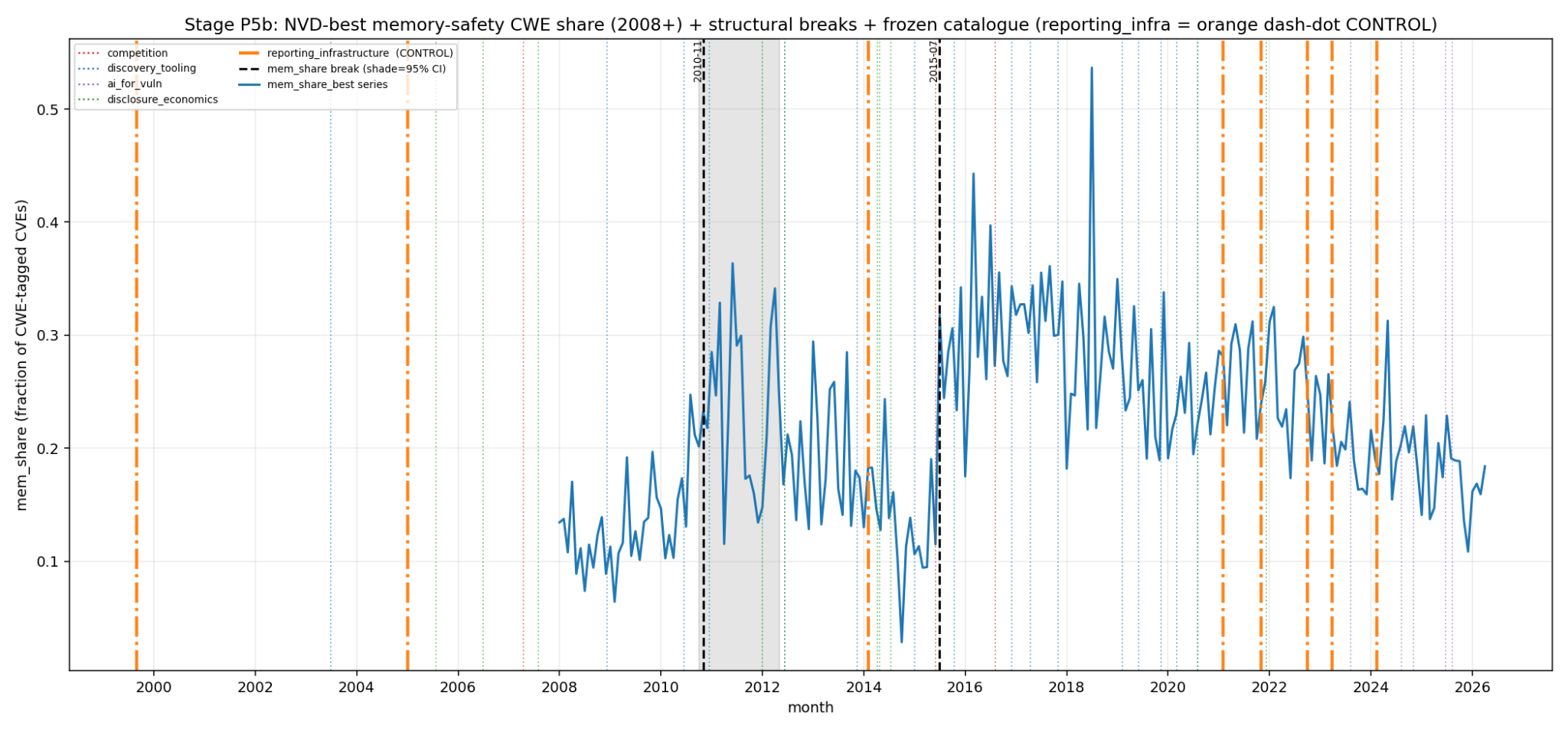
This distinction matters. Absolute memory-safety counts continued to grow: 1,645 in 2016, 4,171 in 2017, and roughly 7,800 in 2025. But that is not evidence of a continuing fuzzing-driven discovery acceleration. The entire vulnerability catalogue expanded. Every major class was lifted by reporting-infrastructure growth and by the growth of the software universe itself.
The share is the more trustworthy discovery-mix signal. On that signal, the fuzzing/competition cohort produced a durable one-time step up, not endless acceleration.
Reporting exploded, but that is not the same as discovery
Total published CVEs were roughly flat at about 6,500 per year through 2014–2016. Then the count jumped to 14,642 in 2017 and kept climbing: 16,510 in 2018, 18,363 in 2020, 25,000 in 2022, 39,930 in 2024, and 48,171 in 2025. That is roughly a 7.5× increase over 2016.
A naive reading says: vulnerability discovery exploded. I think that is mostly wrong.
My read is that the post-2017 surge is dominated by three forces:
reporting-infrastructure expansion, including CNA federation and later CVE JSON changes;
growth in the software universe, visible through the graphed rough proxies like Debian packages, GitHub repositories, and Common Platform Enumeration (CPE) products;
a shift in reporting mix toward web and application classes.
The dual-axis graph view makes this point directly. During the 2015–2017 cohort, the raw CVE rate is flat while the software universe is already climbing. After 2017, the CVE curve rises alongside software-universe and reporting-capacity curves, not clearly ahead of them. That pattern looks less like a permanent increase in discovery efficiency and more like scale, bookkeeping, and a larger attack surface being pulled into the reporting stream.
The net of the 2017 episode is this: the cohort produced a one-time upward shift in the memory-safety discovery fraction, roughly 0.20 to 0.31 from 2015 to 2017, and then the composition stopped accelerating. The post-2017 era is dominated by reporting-pipeline scale-up and drift toward web-class vulnerabilities, not by continuous automated-discovery regime change.
There is an important caveat: NVD’s retroactive tagging-rate co-break around 2016 inflates post-2017 absolute counts. That is why the 2016–2017 jump is mixed. It is also why I trust the memory safety vulnerability share trajectory more than the raw count trajectory.
What 2017 teaches us
The 2017 lesson is not “new tools do not matter.” They do.
The lesson is that new discovery tools harvest the bug classes they are structurally good at finding. The harvest can be large, and it can create a real step change. But unless the tool class keeps expanding into new bug categories faster than the ecosystem can adapt, the discovery share eventually normalizes.
That is what appears to have happened with fuzzing and symbolic execution. The tooling found a lot of memory-safety bugs quickly. Then the easy tranche was depleted, maintainers adopted the tools, targets hardened, and the public reporting system expanded into other classes.
I suspect the reporting lag in 2017 came from a mix of coordinated disclosure windows, vendor patch timing, and the time required for new tooling to spread through real workflows. I do not have enough data to prove that mechanism from this dataset alone, so treat it as a plausible explanation, not a measured fact.
What are we seeing with Mythos?
Now apply the same discipline to Mythos.
Anthropic announced Claude Mythos Preview on April 7, 2026. The model had been in internal and limited pre-release testing before that announcement, and the surrounding press has focused heavily on its ability to discover vulnerabilities and produce working exploits. That is worth taking seriously. But the public vulnerability-publication data does not yet show a clean Mythos-driven step change.
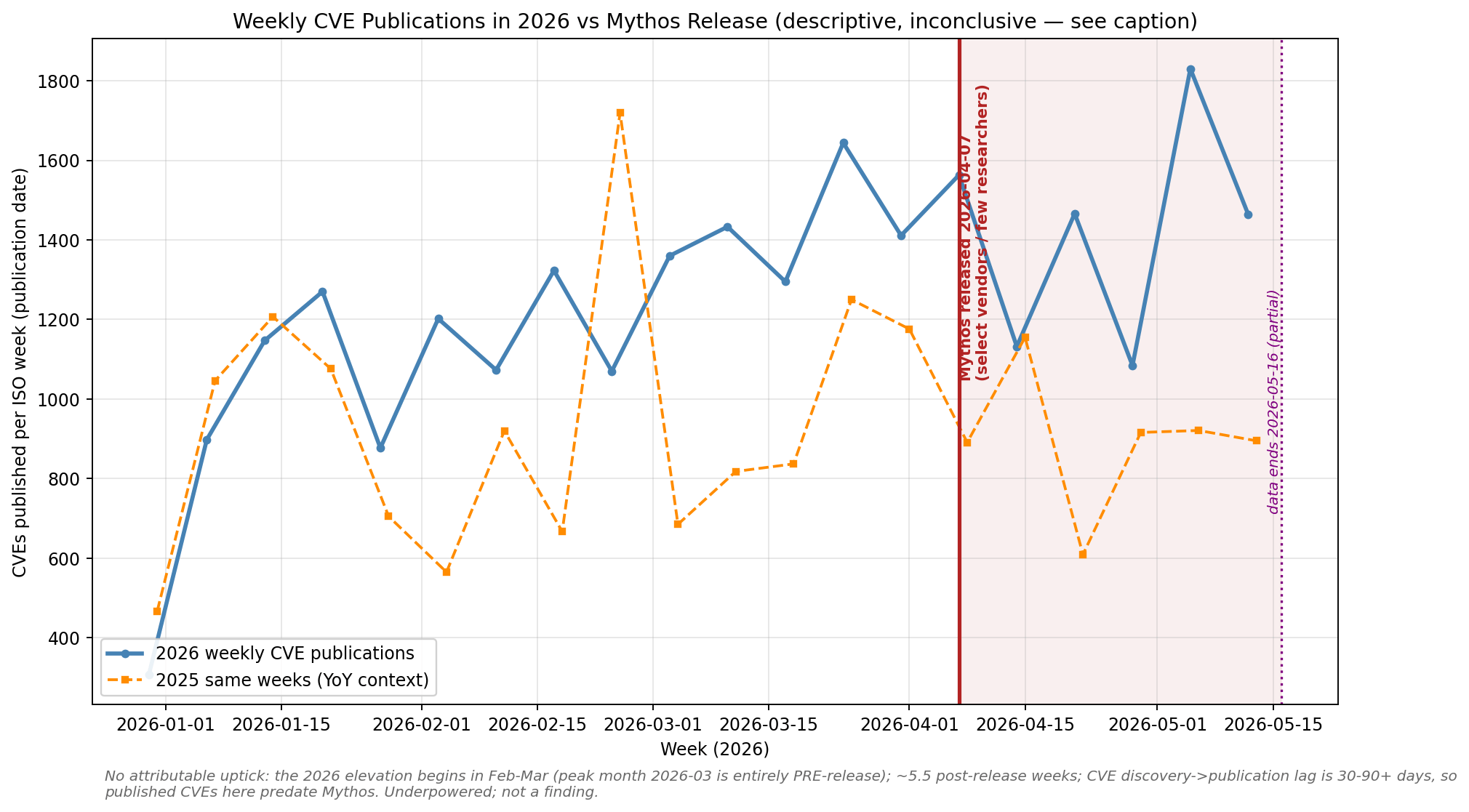
The current public-data read is straightforward:
The 2026 elevation predates Mythos. From January 1 through April 6, before the public Mythos announcement, 2026 was already running 1.26× over 2025. The largest month in the series is entirely pre-release. A rise that begins before the announcement probably cannot be attributed to the announcement unless Anthropic or early partners had already been reporting vulnerabilities without attribution.
The post-announcement window continues the existing trend. April 7–30 and May 1–16 sit at roughly 1.55× and 1.52× year over year. That looks like continuation of the pre-existing 2026 uptrend, not a clean step at April 7. Weekly post-release counts between 1,084 and 1,830 are inside the pre-release range of 1,070 to 1,644.
Reporting lag dominates the signal. CVE assignment and coordinated disclosure commonly introduce 30–90+ day delays. Public CVEs published within roughly five and a half weeks of the announcement overwhelmingly reflect work that began before Mythos was broadly visible. A genuine discovery effect may exist, but published CVE counts are not where it should be expected to surface first.
So: I do not see evidence of a Mythos-driven public-CVE step change yet. That is not evidence that Mythos is overhyped. It is evidence that the public CVE stream is too laggy and too confounded to answer the question this early.
What would change my mind?
The right indicators are not raw CVE totals in the first few weeks after launch. I would look for five signals:
a sustained post-lag break beginning 60–120 days after broader model access;
a composition shift toward bug classes where language models have structural advantage, especially logic bugs, exploit chaining, and cross-component failures;
vendor or CNA attribution showing model-assisted discovery at scale;
deduplicated vulnerability rates normalized by software-universe growth;
a measurable increase in exploitability, not just vulnerability count.
The fifth signal is the important one. Fuzzers and symbolic execution changed the economics of finding memory-corruption bugs. Mythos-class models may change the economics of turning vulnerabilities into reliable exploits.
That is a different and more dangerous regime.
The real discontinuity: exploit generation
The weak version of this argument is: “Mythos will not matter because fuzzing shocks eventually normalized.” That is not my argument.
My argument is narrower: public CVE counts are not yet evidence of a Mythos-driven discovery shock, and history suggests that discovery shocks can be real without producing permanent acceleration.
But Mythos-class exploit generation is not just another discovery tool. Automated exploit construction, especially multi-vulnerability chaining, changes the value of a vulnerability. A bug that was previously “interesting but hard to weaponize” may become operationally relevant if the exploitation work becomes cheap, fast, and repeatable.
That is what we have not seen before at this level.
If Mythos-class models create a discovery uplift, history suggests the uplift may pass after the first harvest. But if they make exploit generation cheap, the security consequences will not be limited to a temporary increase in CVE volume. The center of gravity moves from “how many bugs can we find?” to “how quickly can we convert known or newly found bugs into working exploit chains?”
That is the step change I am watching for but do not have the data to measure.
Conclusion
Mythos and peer-grade cybersecurity models may eventually cause a real step change in vulnerability discovery. That would not be unprecedented. The 2015–2017 fuzzing and cyber-competition cohort already produced a visible discovery-side shift, especially in memory-safety vulnerabilities.
But we do not yet have public CVE data showing that Mythos has created a new reporting-regime break. The 2026 elevation predates the public release, the post-release window is still too short, and disclosure lag makes the published-CVE stream the wrong near-term sensor.
The more important question is not whether Mythos makes vulnerability discovery numbers go up for a while. It probably will, if deployed broadly enough.
The important question is what happens if (and when?) Mythos-class models make exploit generation routine.
That is the part that we have never seen before.